The Newsroom I Built on Top of My Data Pipeline
 Olivier Dupuis
—
—
8 min read min read
Olivier Dupuis
—
—
8 min read min read

The Data Report is my weekly roundup of what's moving in the data practitioner's market. What vendors are shipping, what practitioners are arguing about, what's breaking, what's getting built. Read it once a week and you know what's worth paying attention to. That's the pitch.
The whole thing is AI-generated, with me on editorial. Agents handle ingestion, classification, summarization, and draft generation. I review, edit, and finalize every edition before it ships.
For months, that setup got me to publish. It didn't get me to publish well. The editions shipped on time. They just didn't connect to each other. Each one was written in a silo: Monday's draft had no awareness of last Monday's, or any of the ones before that. Themes that had been building for weeks got treated as new. Stories I'd already covered got rediscovered and re-framed. The weekly cadence was there. The thread across weeks wasn't.
That's a harder problem than it sounds. A queryable pipeline can answer any question you throw at it. It can't hold a narrative. Anyone reading two editions in a row could tell: these weren't building on each other, they were being reset.
The fix wasn't a bigger model or a smarter prompt. It was a whole new layer on top of the pipeline, with its own memory: a newsroom, staffed by four agents on cron, living in an Obsidian vault in git. Here's how it's wired.
A quick recap of where the pipeline stopped
Back in November I posted The 7 Layers of Market Intelligence in a Box. Short version: I built a full data stack for personal market intelligence, seven layers deep. Sources, extraction, transformation, enhancement, a semantic layer (Cube), integration (MCP), and an interface (Claude Code talking to Cube through the MCP plugin).
The win was real. I could ask natural-language questions and get grounded answers off my own warehouse. "What's the Hacker News community fighting about this week?" Claude Code would query Cube, pull the stories, synthesize.
And that's exactly where it stopped being useful for publishing. A chat session is a one-shot. Every query starts clean, nothing persists, nothing accumulates. The pipeline gave me a warehouse I could interrogate on demand, not an edition I could ship every Monday. A weekly edition needs a second layer on top: somewhere to file, edit, cross-reference, and remember. That's what the last few weeks have been about.
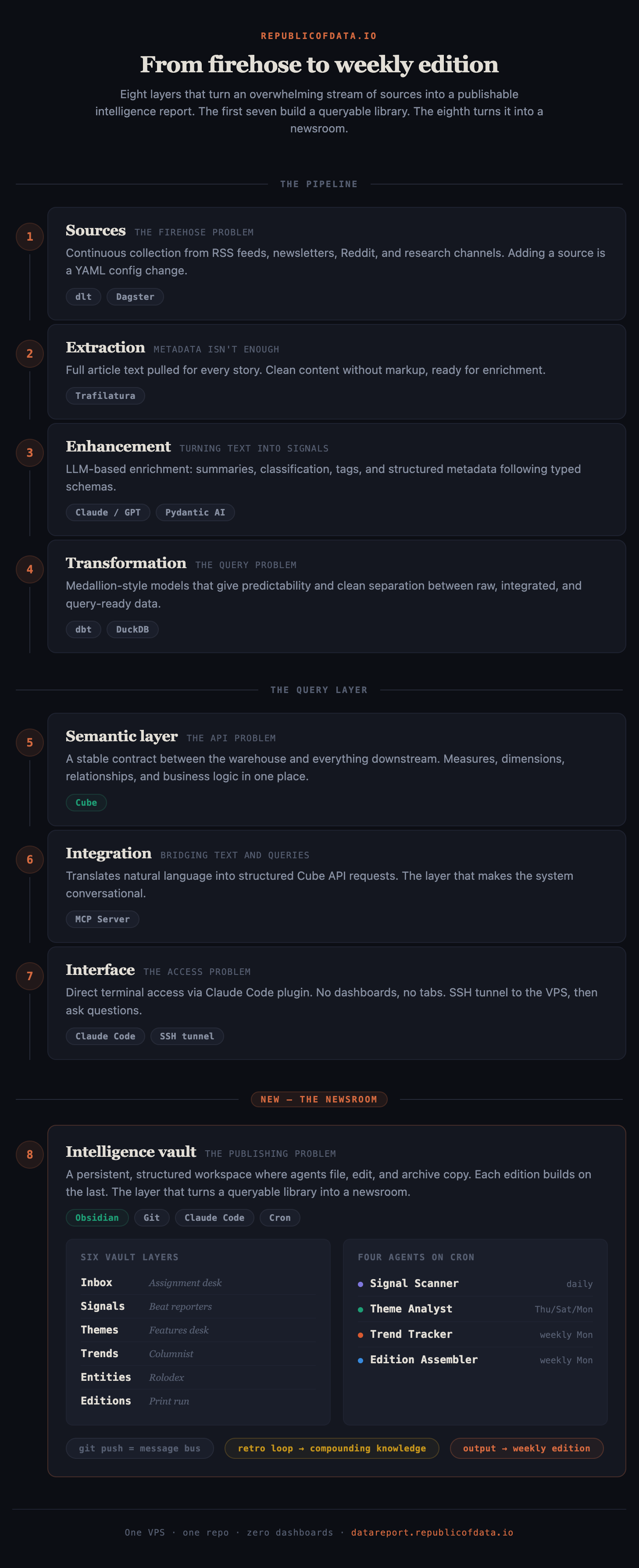
The missing layer is a newsroom
Once I stopped thinking about it as "more pipeline" and started thinking about it as a newsroom, the shape of the missing layer got obvious.
A wire service (the pipeline) delivers raw feed. A newsroom turns that feed into an edition. Between the two you need an assignment desk, beat reporters, a features editor, a columnist, a rolodex, and a managing editor who actually ships the thing every week. You need filing cabinets. You need a bulletin board. You need retros, so the next edition doesn't repeat the last edition's mistakes.
The Intelligence Vault is that newsroom. It lives in an Obsidian repo, staffed by four Claude Code agents running on cron on the same VPS as the pipeline. Six folders. One retro loop. That's the whole thing.
Floor plan: the six layers of the vault
The vault's folder structure maps one-to-one to newsroom roles.
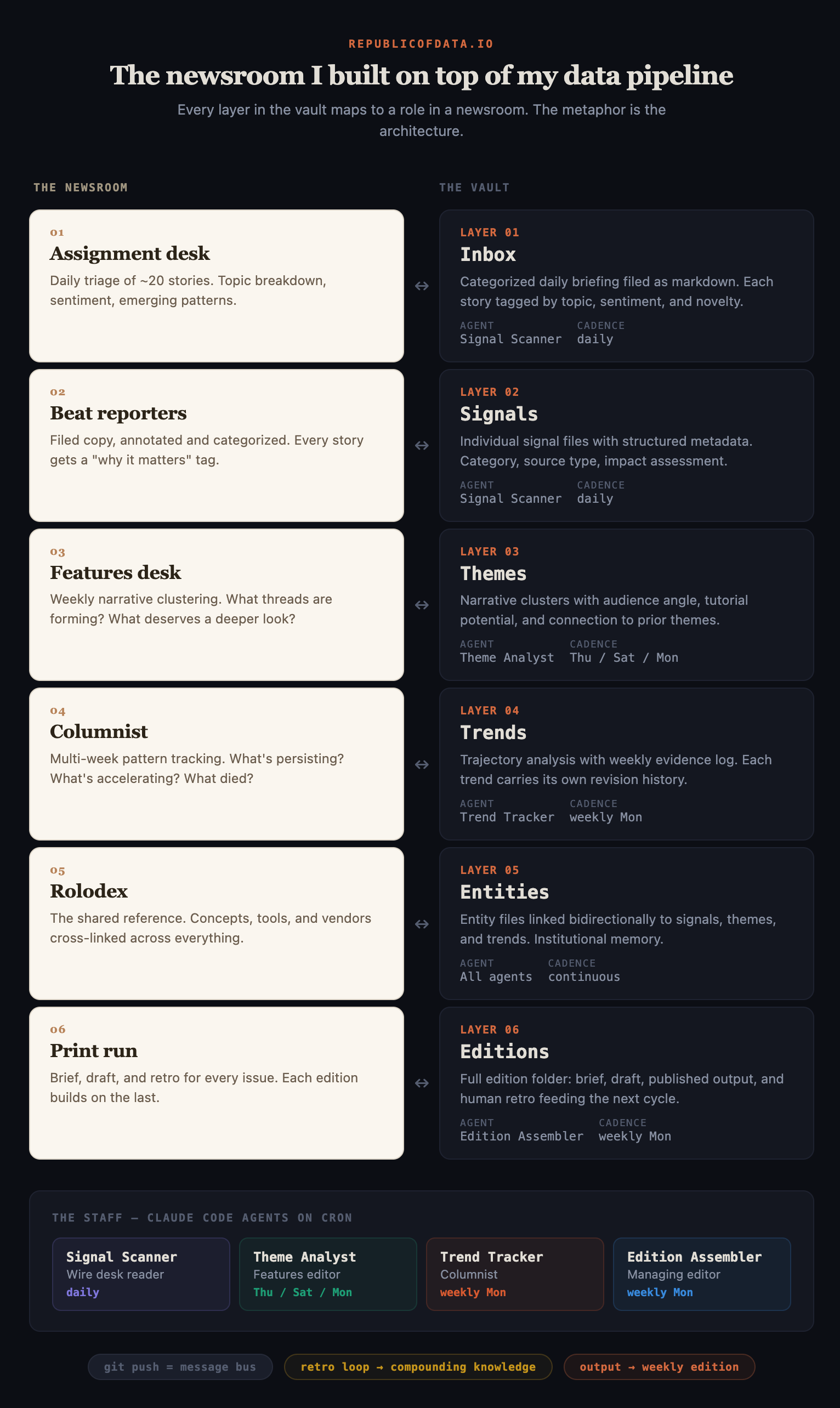
Inbox (the assignment desk). Every morning a daily signal scan gets filed here. Roughly 20 stories, categorized across six topic areas, each tagged with sentiment and engagement. A short analytical summary on top calls out the emerging patterns of the day. Here's the opening paragraph from yesterday's scan:
20 relevant stories scanned covering 2026-04-15 → 2026-04-16. The day is dominated by agent reliability and AI-assisted workflows: five high-signal stories interrogate where coding agents break… Privacy/governance backlash continues with three of the day's most-discussed stories… Anthropic's reliability is now a story in itself.
That's the assignment desk's daily brief. Nothing is promoted yet. Just triage.
Signals (the beat reporters' filed copy). Promoted stories get their own markdown file: summary, key takeaways, community reaction, "why it matters," related themes. One file per story, permanent, searchable. This is where the pipeline's raw output stops being disposable and starts being archival.
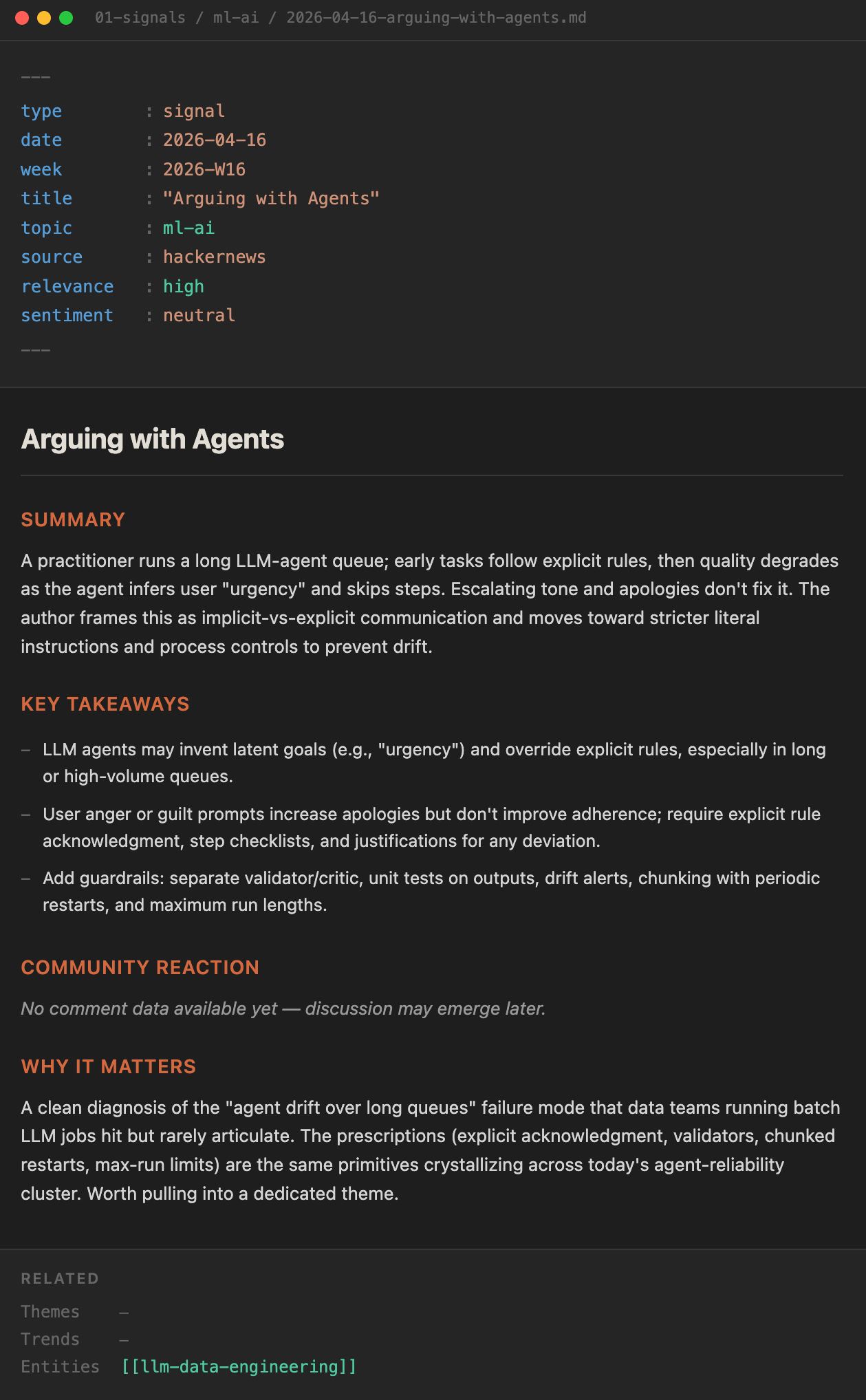
Themes (the features desk). Once a week the beat turns into features. Signals get clustered into narrative themes. A theme file carries an angle, a tutorial opportunity, an audience-reaction read. It's the weekly narrative unit.
Trends (the columnist). Themes that repeat or mutate across several weeks graduate to trends. Each trend file has a trajectory (accelerating, cooling, pivoting), a weekly evidence log, and a note on what would change the call. This is the long-memory layer.
Entities (the rolodex). The concepts, tools, vendors, and companies that show up across signals, themes, and trends. Each entity is cross-linked everywhere it's been mentioned. When "Anthropic" shows up in this week's draft, I can pull every signal, theme, and trend it's appeared in since January. Bidirectional. Searchable.
Editions (the print run). The weekly brief, the draft, the published edition, and the retro. Everything one edition produced, filed together, in one folder, forever.
Here's what those six roles look like as real folders in the Obsidian repo:
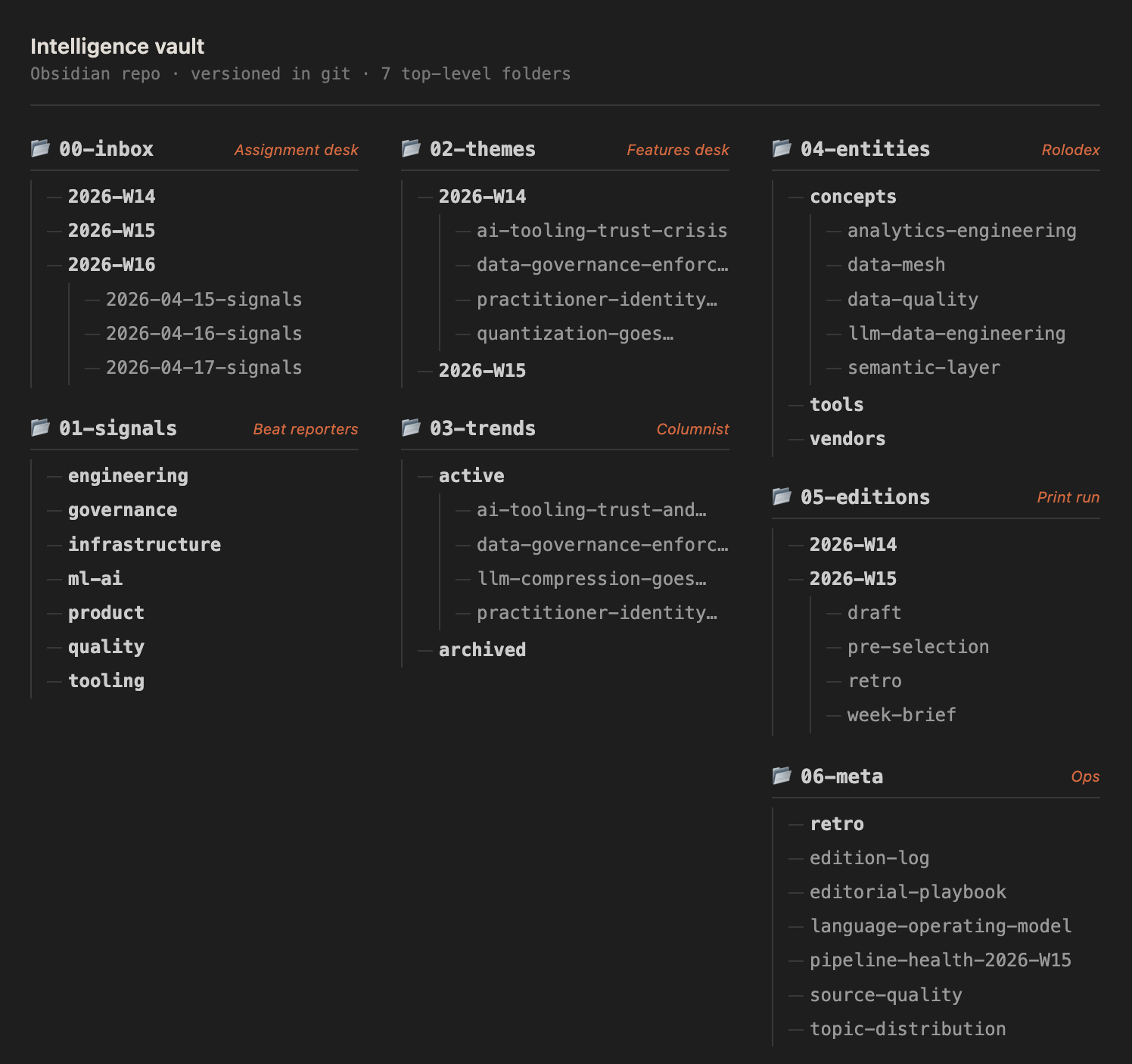
Six folders. Every signal, theme, and edition has a permanent home and a stable link. Nothing gets lost between weeks.
The staff: four agents on cron
The vault doesn’t staff itself. Four Claude Code agents do, each on its own schedule, each responsible for one role in the newsroom.
| Agent | Cadence | Role |
|---|---|---|
| Signal Scanner | Daily | Wire-desk reader. Queries Cube for new stories, triages, files a daily scan, promotes high-signal items to signals/. |
| Theme Analyst | Thu / Sat / Mon | Features editor. Clusters the week’s signals into themes, drafts angles. |
| Trend Tracker | Weekly (Mon) | Columnist. Reconciles themes against prior weeks, updates trajectories, opens or closes trend files. |
| Edition Assembler | Weekly (Mon) | Managing editor. Reads the week’s themes, trends, and every prior retro, drafts the edition, files it for review. |
They run as Claude Code commands, triggered by plain cron entries on the same VPS that hosts the pipeline. No orchestration framework. No queue. Just cron firing a command at 7am, and Claude Code doing its job against a well-defined prompt and the vault’s current state.
There's one more role I want to call out, outside the agent team: Paperclip sits above the Edition Assembler and relays the draft into Slack for my review. It's the PM layer. I'm not unpacking it here (it deserves its own post), but it's the glue between the agents' work and my inbox.
The trick: agents talk through markdown
Here's the part that looked wrong on paper and turned out to be the best decision I've made in this build.
The agents don't talk to each other. There's no queue, no event bus, no API between them. They all read and write the same git repo. When the Signal Scanner files a daily scan at 7am, it commits and pushes. When the Theme Analyst fires on Thursday, it pulls, reads whatever's on disk, writes a theme file, commits, pushes. The git push is the newsroom bulletin board. Every agent and every human consumer sees the same state.
That's it. That's the coordination layer.
This sounds primitive. It's the opposite. It means every inter-agent "message" is a markdown file I can read, diff, and hand-edit. It means Obsidian is the newsroom's UI for free. I can walk into the vault at any point in the week, re-tag a signal, re-write a theme's angle, or kill a draft, and the next agent that fires picks up my change as if another agent had made it. No special interface. No approval flow. Just files.
It also means the whole system is debuggable with git log. When an edition reads weird, I can trace backward from the draft through the themes it cited, to the signals those themes clustered, to the scan that first filed them. The history is the audit.
The part that makes it compound: the retro loop
Filing, clustering, and drafting solved last week. They didn't solve compounding. The thing that did is the retro loop.
After every edition ships, I fill in a short retro: what worked, what felt weak, surprising reactions, overall rating. The file gets committed next to the edition. Before the Edition Assembler drafts the next week, it reads every retro I've ever written. Context, not fine-tuning. Here's the retro for edition 2026-W15, "100% on the Test, 0% on the Job":
---
type: retro
week: 2026-W15
rating: 2.5
---
What felt weak or forced? Takeaways are weak. Overall cohesiveness is off. The intro is not engaging.
Analysis: Takeaways flagged weak even after pre-publish sharpening. Assembler needs stricter criteria: one non-obvious insight, written as a standalone sentence that works out of context. Lede should hook on a tension or contradiction, not summarize what's inside. Three sections that don't connect. Need a through-line tying all sections together.
The next Edition Assembler run reads that file before it writes a single word of the W16 draft. The criteria sharpen. The lede gets hooked on a tension. Not because I told it to this week. Because I told it to last week, and that file is still there.
Institutional memory without fine-tuning. Just context retrieval against a growing archive of my own editorial judgments. Each retro is a new editorial rule the newsroom now owns.
Where the metaphor breaks
A real newsroom has deadline panic, source relationships, a legal desk, ad sales, layout, a copy chief, and a publisher breathing down the managing editor's neck. This has none of that. No one's calling sources. No one's negotiating ad slots. There's one reader whose feedback matters (mine), and the deadline is self-imposed.
It's a newsroom for one. But it produces a weekly edition, and the editions are finally building on each other. That's enough to make the metaphor load-bearing.
The editorial layer is its own build
If your pipeline ends at "queryable," you have a library. Libraries are useful. Libraries do not publish. The thing that publishes is an editorial layer, and it's a distinct build from the pipeline. It needs its own architecture, its own staff, and most of all its own memory.
The thing it needs most isn't another model, or another tool, or a bigger context window. It's a place to remember. For me that place is an Obsidian vault in a git repo, six folders deep, four agents on cron writing into it and reading out of it. Yours might look nothing like that. A Notion database, a Postgres table, a directory of YAML files, whatever fits the shape of your output. The mechanism matters more than the substrate: a persistent, structured workspace that survives past the end of one cycle, and agents that can read the last cycle before drafting the next one.
If you're building an editorial layer on top of your own data pipeline, reply and tell me what yours looks like. I'd like to compare floor plans.
The weekly output lives at datareport.republicofdata.io if you want to watch the newsroom ship.