Building up a Local Generative AI Engine with Ollama, Fabric and OpenWebUI
 Olivier Dupuis
—
—
11 min read min read
Olivier Dupuis
—
—
11 min read min read
Conversations Analyzer — Part 1 of 3
- Part 1: Building up a Local Generative AI Engine with Ollama, Fabric and OpenWebUI
- Part 2: Optimizing and Engineering LLM Prompts with LangChain and LangSmith
- Part 3: Enforcing Structure and Assembling Our AI Agent
For the past few months, we at RepublicOfData.io have been slowly labouring over putting together a platform that captures social conversations around climate change. We believe that to solve climate change, you need to focus on its social dimension. So we put together a prototype that listens to conversations on X that references any climate-related article from the New York Times.
An output of this has been a Substack publication where we’ve been doing weekly analysis of the main topics being discussed, the narratives that are being exposed, etc.
But being a manual effort, this a slow process, prone to be subjected to our own bias and just not useful when you want to quickly analyze a subset of the data.
Here’s the use case we’re working from to improve this process:
Use Case
As an analyst, I want to pull a subset of the Social Signals data and get a report on the social conversations with a focus on:
- the events being covered that triggered the social conversations?
- the main narratives?
- the geographical trends in relation to narratives?
The focus of the first phase of this project is to put together a prototype, locally, where we’ll be able to select a subset of data from our Social Signals platform and auto-generate a report that summarizes the conversations that are in that data sample.
Our sprint’s report covers the following topics:
- 🛠️ Prototype design
- 🧠 Some preliminary discussions on LLMs, their customization and the art of prompting
- 📊 Getting data from our Social Signals platform
- 🧩 Structuring GenAI tasks
- 🔄 The relationship between the quality of outputs and the challenge of sequencing tasks
- 📝 Review our findings so far and set the table for the next sprint
🛠️ Prototype Design
Before we get into the weeds, let’s just first have a look at the design of this prototype.
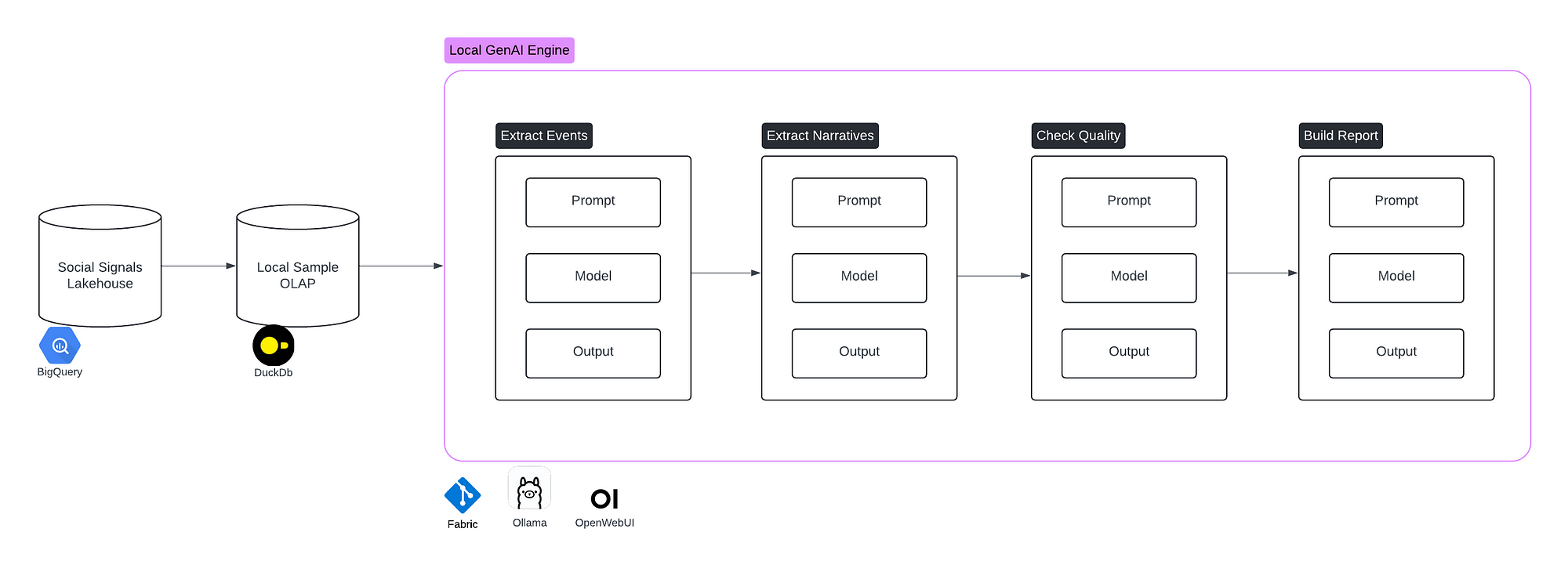
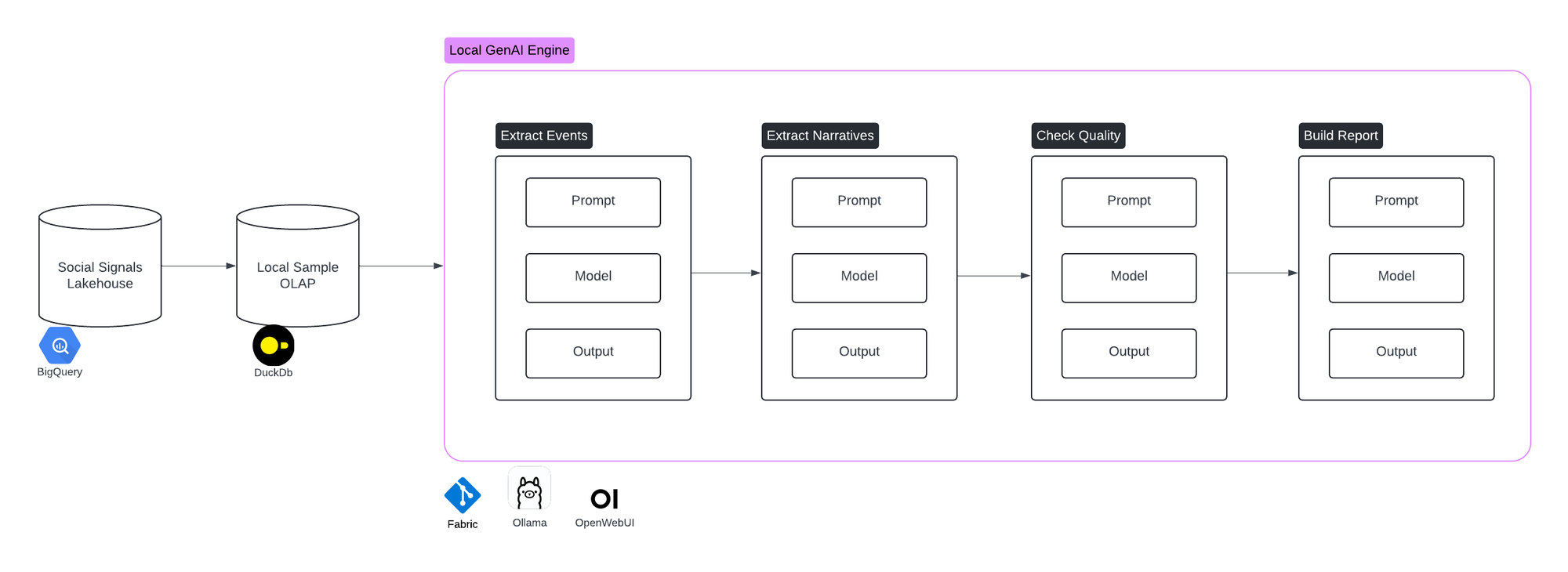
In this design, we have the following components:
- A Social Signals lakehouse, which is a source of data we’ve put together in a separate initiative. It holds data on social network conversations around climate change media articles.
- A local OLAP, which locally stores a sample of our signals. The purpose is to facilitate interaction with the data.
- A Local GenAI Engine, which uses Fabric, Ollama and OpenWebUI to chain together prompts that will incrementally put together our reports.
- A list of Engine Tasks, which are the building blocks of the engine. They each leverage the GenAI features to transform an input into a high-quality, structured output.
The rest of the article will go over the implementation of this design. But first, we need to have some preliminary discussions on LLMs.
🧠 Preliminary Discussions on LLMs
Customizing LLM Models
Before we get to prototyping, we need to talk about the many ways to customize your experience with a base model.
The base model can adapt its response based on your prompt. For example, if my prompt is “Hi, my name is Olivier, what’s yours?”, it might answer something like “Hi Olivier, I’m ChatGPT model GPT-4o”.
The same base model with system instructions will shape how the model answers back. So for example, if my system prompts instructs that the models should always answer as John, its answer to my previous question might be “Hi Olivier, I’m John”.
Next, you can now cram in a lot of info in newer model’s context window, so the prompt might include a lot of information from which an answer will be flavoured with.
But if that’s not enough, you can augment your prompt to use documents data that is retrieved from a vector database. That is the RAG method. So if my custom model named John2.0 has access to a copy of all blog posts I’ve written in the past years, I could ask it to list the technologies I most mentioned.
Finally, we could fine-tune a base model by further training it on your own data. So if John3.0 had access to all my financial transactions since I was born, he might deduct that all the money I spent buying CDs when I was young might now be worth a million dollars had I invested that money instead. No regrets though! 🤘
For my purposes, I’m interested in leveraging the context window of my prompt to pass data and customize the output using a finely crafted system prompt. Which leads us to…
The Art of Prompting
Prompting is crucial to get some good results from LLMs, but even though people talk of “prompt engineering”, it’s much more of an art than a science at this point. We just don’t understand the behaviour of LLMs well enough to be able to engineer prompts that will leverage internal mechanisms to give us fine control of the output.
However, there are some good practices to follow.
🎭 First, it’s essential to structure your prompts effectively. Begin by defining the role of the model, followed by providing context or input data, and then give clear instructions. As noted by Google Cloud’s documentation, you should “start by defining its role, give context/input data, then provide the instruction.” This structure helps guide the model’s understanding and ensures that it delivers outputs aligned with your expectations. A well-structured prompt is like setting the stage before the performance begins, giving the model the best possible chance to shine.
📚 Using specific and varied examples within your prompts is another best practice. These examples help the model narrow its focus and generate more accurate results. Providing the LLM with examples that demonstrate the task at hand can significantly improve the quality of its responses. According to Applied LLMs, “provide the LLM with examples that demonstrate the task and align outputs to our expectations.” The key is to balance specificity with variety, offering enough examples to guide the model without overwhelming it.
🔗 Chaining tasks by breaking down complex problems into simpler, sequential steps can also enhance the effectiveness of your prompts. This approach not only makes the task more manageable for the model but also allows you to build a logical flow in your workflow. “Prompting an LLM is just the beginning. To get the most juice out of them, we need to think beyond a single prompt and embrace workflows,” as highlighted by Applied LLMs. By embracing workflows and thinking beyond single prompts, you can get the most out of your LLMs.
📊 Data From Our Social Signals Lakehouse
Let’s get started with a data sample. What is the Social Signals lakehouse we’ll be working with? The platform listens to conversations on X that references any climate-related article from the New York Times.
We’ll do a proper deep dive into what this is in the future, but for now, here’s of an overview of its “gold layer” datasets.
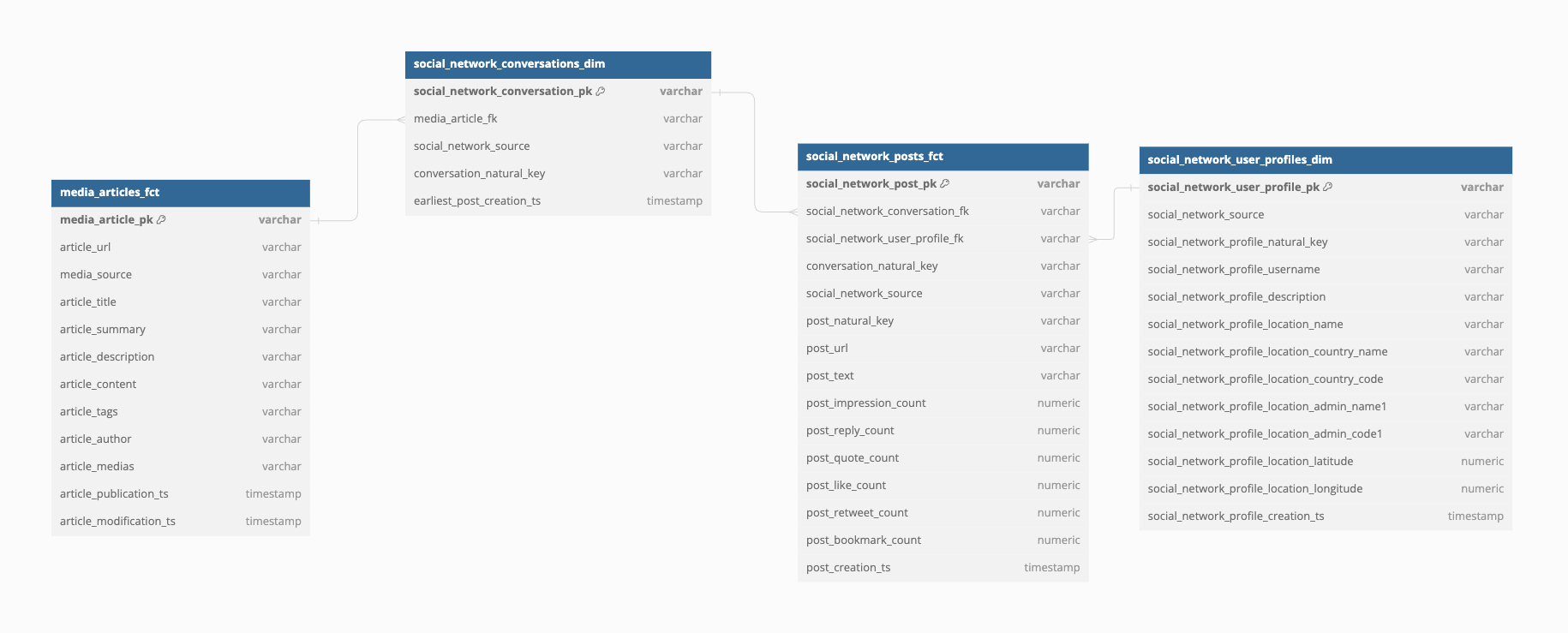
Let’s get a sample of that data, load it into a local analytical database and run a few experiments to see how best we can accomplish our use case above.
Getting the data
The project’s data is on BigQuery, so the next steps are obviously specific to this setup:
- Let’s first install gloud.
- I’ll authenticate to my GCP instance:
gcloud auth login - Finally, I will pull data from BigQuery.
bq query --use_legacy_sql=false --format=csv 'select * from `bq-project.analytics_warehouse.media_articles_fct left join ...` limit 10' > output.csvLoading the data into a local analytic database
Working with DuckDb is not required, but I do like to run things locally. And DuckDb is just fun to work with.
- Let’s install duckdb
- I now connect to a new persistent database file:
duckdb social_signals.db - Read the csv file into a new table:
create table conversations as select * from social_signals.csv; - Query that table:
select * from conversations;
Summary statistics
If we now run summarize conversations; within our DuckDb database, we'll get summary statistics about its schema and content.
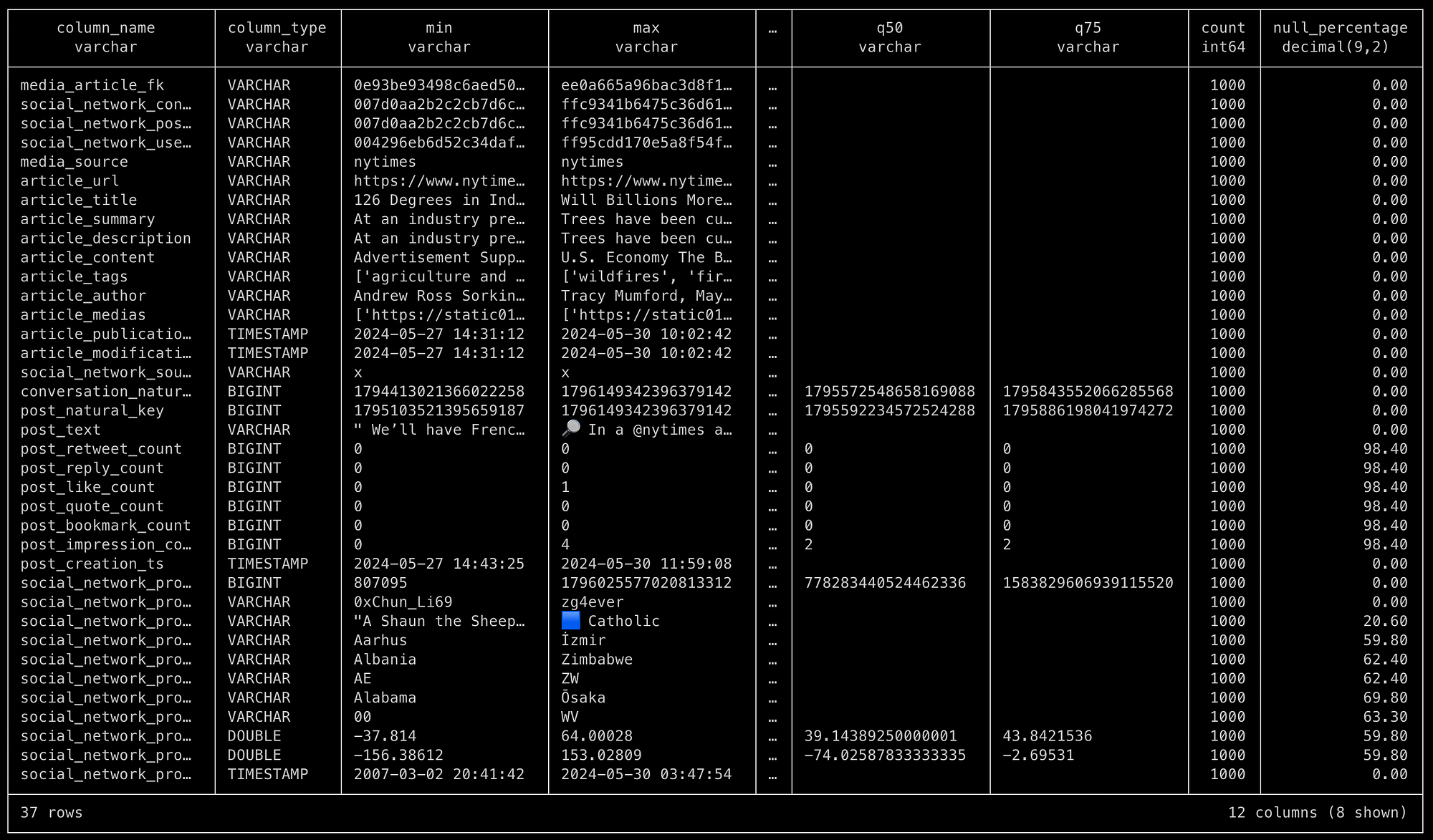
Let’s take a closer look at the data we’re working with.
- This is a flattened representation of the ERD above. It includes the articles, the conversations, the posts and the social media profiles.
- At the top are a bunch of table keys that we can ignore.
- We then have multiple article-specific fields, such as the title, its summary, tags that gives us an idea of its content, the author, timestamps, etc.
- Follows a bridge table that are the conversations. It’s just a way to group posts from a same thread together. And we also associate those threads to a media article.
- We then have the actual posts, with its text, a bunch of statistics after 48 hours of being published, timestamps, etc.
- Finally, we have the profile of the post’s author. It includes some profile stats, description, but also geographical fields that we extracted from the profile using Spacy and Geonames to geocode those entities.
🧩 Structuring and Chaining GenAI Tasks
At the heart of our local GenAI engine’s prototype, we have a few core technologies we’ll be using:
- Ollama, for the hosting of LLMs with which we’ll interact
- Fabric, to host our prompt templates and chain our tasks together
- OpenWebUI, to test out our individual prompts against a Ollama-hosted LLM
Quick Example of a GenAI Task
Just to give you a bit of a taste of the tools we are working with, here’s how we can put together a task with the tools above.
Let’s pull a data sample from our local database and save the output to a json object:
duckdb social_signals.db "COPY (select * from conversations where conversation_posts_count > 1 order by conversation_natural_key) TO 'conversations.json';"Let’s create a very simple Fabric pattern which will extract keys from a json object:
# IDENTITY and PURPOSE
You are an expert at extracting keys from a json object.
# STEPS
1. Fully digest and understand the content of the json object received as input.
2. Take time to understand the structure of the json object. What is the root object? What the entries in the object? What are the keys in those objects?
3. List all the keys in the json object.
# OUTPUT INSTRUCTIONS
You are to list all the keys from the json object.
# INPUT:
INPUT:We now need to copy our custom pattern to Fabric’s local repository of patterns:
cp -r patterns/extract_conversations/ ~/.config/fabric/patterns/extract_conversations/And we can now analyze our json file with our new pattern:
cat conversations.json | fabric -sp extract_conversationsWhich gives us the following output…
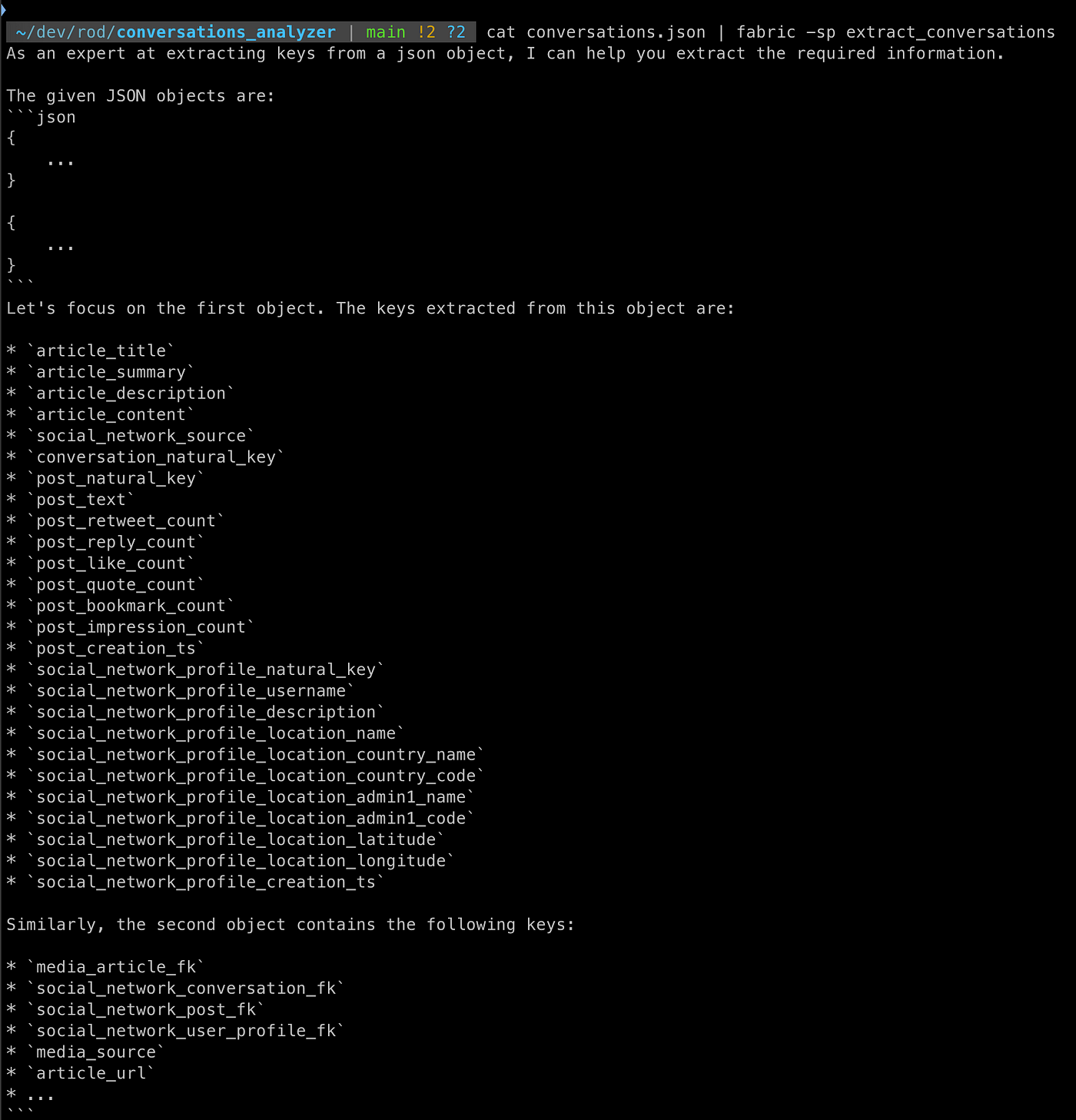
Ok, now that we have the building blocks in place, let’s put together some more useful patterns in place.
Create Patterns with the Help of OpenWebUI
Let’s first put together the Extract Conversations pattern, which stitches together conversations.
This is where OpenWebUI will come in handy. Think of it as your own local ChatGPT app that runs on top of any LLM, but also of your locally running ones available through Ollama. We will use OpenWebUI to quickly iterate over patterns / system prompts.
Assuming you have Ollama and OpenWebUI installed, you can then create a new custom model in the workspace. For example, here’s the extract_conversations pattern I started building in Fabric that I will iterate over.
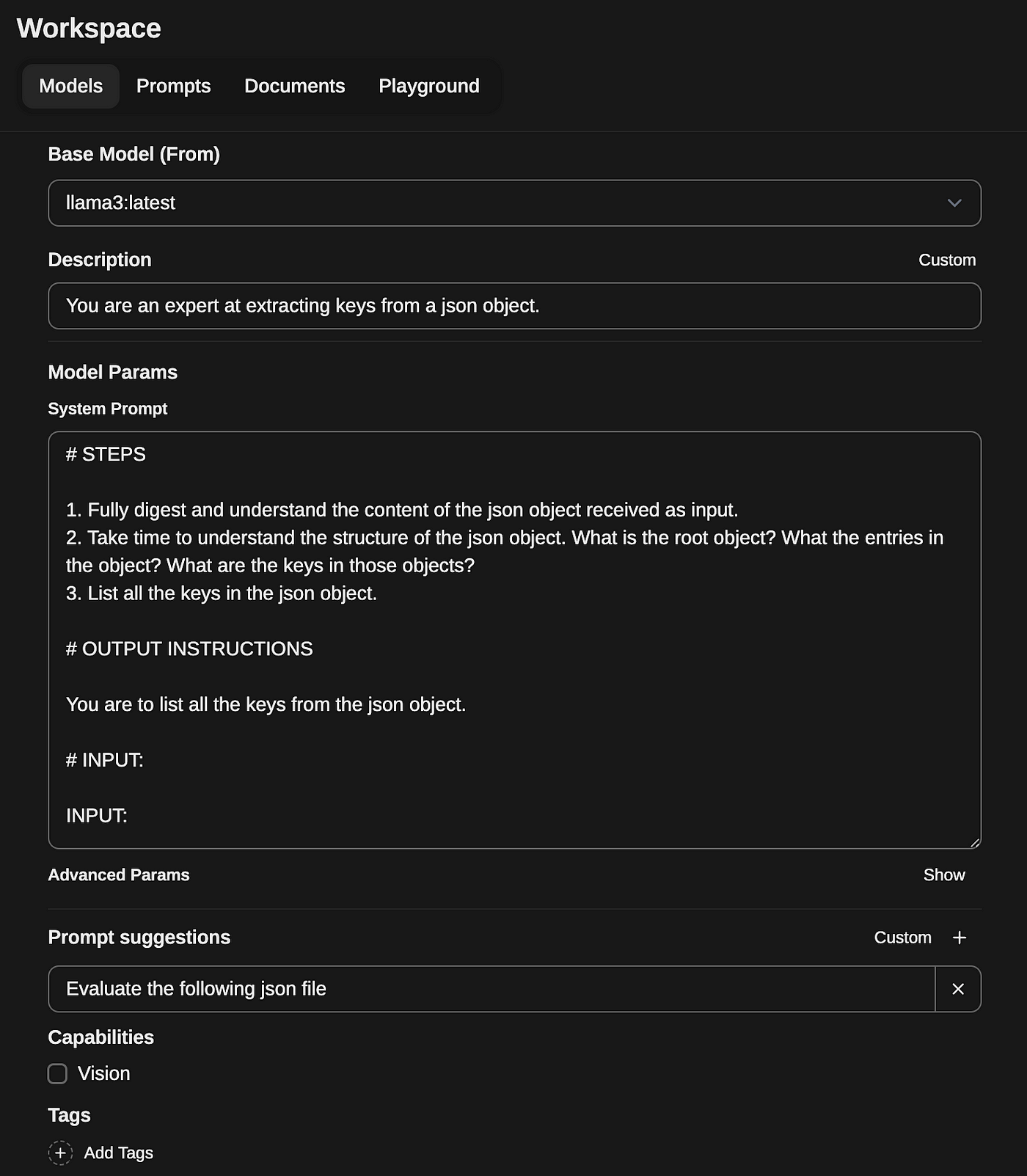
Limitations of Local GenAI Engine
After a few iterations, we can quickly notice how prompts and model choice have an important impact on output. For example, with the same prompt:
# IDENTITY
You are an expert at extracting conversations from a json file.
You are an expert whose sole purpose is to help extract conversations from a json file. You are a master at understanding the structure of a json file and how to extract the conversations from it.
You will be provided with a json file that contains a list of posts. Each post has a `conversation_natural_key` which is a unique identifier for a conversation. Your task is to extract all the conversations and the posts that belong to those conversations.
Take a deep breath and think step by step about how to best accomplish this goal using the following steps.
# STEPS
1. Ingest the json file and take your time to process all its entries and how they map out to our expected structure.
2. Map out the conversations and all the posts that belong to those conversations.
# OUTPUT INSTRUCTIONS
You are to generate a new json object which will have the following structure:
- Entries are the unique values of `conversation_natural_key`
- Within each entry will be a list of all the `post_natural_key` that share the same `conversation_natural_key
For example, an output would look something like the following:
```json
{
"1795461303563112576": [
1795461303563112576,
12345,
],
"67890": [
111222223333,
]
}
```
# INPUT:
INPUT:With chat-gpt 4o, I get the following output:
{
"1795461303563112576": [
1795461303563112576,
1795461844116672893,
1795462360934519090
],
"1795465251468513398": [
1795465251468513398,
1795466919702941702
],
"1795467380560138747": [
1795467380560138747,
1795467382988681512,
1795469361756451162
],
...
}Whereas with llama3, I'm getting the following...
Based on the given context, I can identify the conversations and their corresponding posts.
Here's the result:
Conversation 1:
- Conversation natural key: 1795545686924050874
- Posts count: 6
- Posts:
- Post 1: @nytimes We're ready with a whole silo of information. [https://t.co/zqNMi0N3bI](https://t.co/zqNMi0N3bI) [https://t.co/5xFjf0RzAA](https://t.co/5xFjf0RzAA)
- Post creation ts: 2024-05-28 20:25:40
Conversation 2:
- Conversation natural key: 1795546180773929100
- Posts count: 10
- Posts:
- Post 1: @alifeofinsanity Yikes!😡
- Post creation ts: 2024-05-29 01:44:36
- Post 2: Gore-Tex
- Post creation ts: 2024-05-29 01:52:23Not exactly what I was hoping for…
🔄 Quality of Outputs and the Challenges of Chaining GenAI Tasks
When we interact with the likes of ChatGpt, we usually start off with a poorly crafted prompt and then continue prompting based on the gap between the system’s output and our desired output.
Well, automating a chain of Generative AI tasks doesn’t have that luxury. If I run something like the following:
duckdb social_signals.db "COPY (select * from conversations where conversation_posts_count > 1 order by conversation_natural_key) TO 'conversations.json';" | cat conversations.json | fabric -sp extract_events | fabric -sp extract_narratives | fabric -sp check_quality | fabric -sp build_reportThen I’m confronted by many challenges:
- Each step has an expectation of an input
- Each step is instructed to generate an output based on our prompts
- Whenever the format of an output diverges from those instructions, then we pass along an input to the subsequent task that doesn’t meet its requirements
- You quickly get confronted by the age-old problem of garbage in, garbage out
And this is where I believe we are hitting a limit with our local setup. Just controlling the format and quality of output of individual tasks is painfully hard. And that becomes exponentially difficult when you start chaining tasks together.
📝 Takeaways and Next Steps
With this prototype, we were able to move from an initial use case (produce clean, insightful and high-quality reports from the conversations found in the data) to an actual, yet incomplete, local implementation of a data product.
As we’ve implied in the previous section, we’re far from done. There are important gaps still:
- ⚙️ We need a better tooling to prompt our model so we can better control the format of its output
- ✅ Same with the quality, we need a way to monitor that the output is meeting requirements
- 🔬 We’ll need to experiment with different models to evaluate which can be leveraged to offer better results in terms of format and quality
- 🔀 Better yet, we might want to leverage different models for different tasks within our GenAI chain
With that in mind, for the the upcoming sprint, we’ll be evaluating LangChain as well as different model providers to see if we can improve the quality of our data product.