Enforcing Structure and Assembling Our AI Agent
 Olivier Dupuis
—
—
9 min read min read
Olivier Dupuis
—
—
9 min read min read
Conversations Analyzer - Part 3 of 3
- Part 1: Building up a Local Generative AI Engine with Ollama, Fabric and OpenWebUI
- Part 2: Optimizing and Engineering LLM Prompts with LangChain and LangSmith
- Part 3: Enforcing Structure and Assembling our AI Agent
This is the last part of our series on creating a data product to analyze online discussions about climate-related events, laws, and initiatives.
Our goal is to develop an AI agent that summarizes conversations by highlighting their main narratives and supporting arguments.
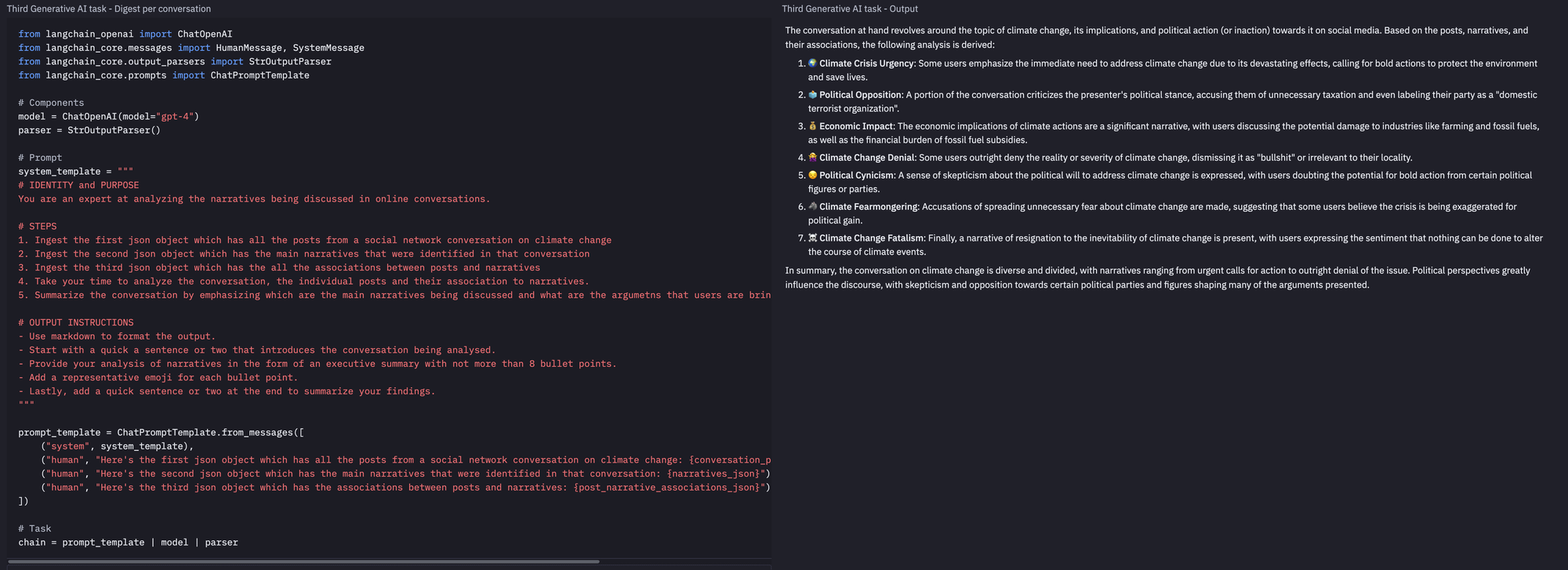
Once completed, our agent will output summaries such as this one:
The conversation being analysed revolves around the topic of climate change, in response to a comment made by a politician. The participants in the conversation express a range of perspectives on the issue, from urgency in addressing the crisis to skepticism and denial of its existence.
Here's a summary of the main narratives identified in the conversation:
🚨 Climate Crisis Urgency: There are calls for immediate action on climate change, emphasizing the severity and immediate repercussions of the issue.
🥊 Political Dispute: The dialogue contains strong disagreements on the politicization of climate change, with users blaming various political figures and parties for the current state of affairs.
🙄 Skeptical of Climate Change: Some participants express skepticism towards climate change, questioning its validity and severity.
💰 Economic Concern: There is concern about the potential economic impact of climate action, with mentions of potential industry collapse and increased taxation.
⛽ Fossil Fuel Subsidies: Some users are calling for an end to fossil fuel subsidies, highlighting their contribution to climate change.
🙅♀️ Disbelief in Political Action: A narrative of doubt about the ability of politicians to take bold action on climate change is present.
🗣️ Criticism of Fear Mongering: Some participants criticize the climate change discourse as fear-mongering, referencing past climate predictions that didn't come to pass.
🚫 Climate Change Denial: There are posts denying the existence or severity of climate change, with mentions of people moving to warmer climates.
💬 Ideological Semantics: Accusations of ideological semantics in climate change discussions are present, with calls for more intelligent conversations.
📚 Climate Change Information Source: Some posts share resources related to climate change, aiming to inform others about the issue.
In summary, the conversation is a complex mix of narratives, reflecting the diverse perspectives on climate change. These range from urgent calls for action and policy change to skepticism, denial, and accusations of fear-mongering. The conversation highlights the contentious nature of climate change discussions, as well as the broad range of understandings and beliefs related to this critical global issue.This agent relies on Generative AI tasks chained together. As a reminder, this is the architecture we're working with.
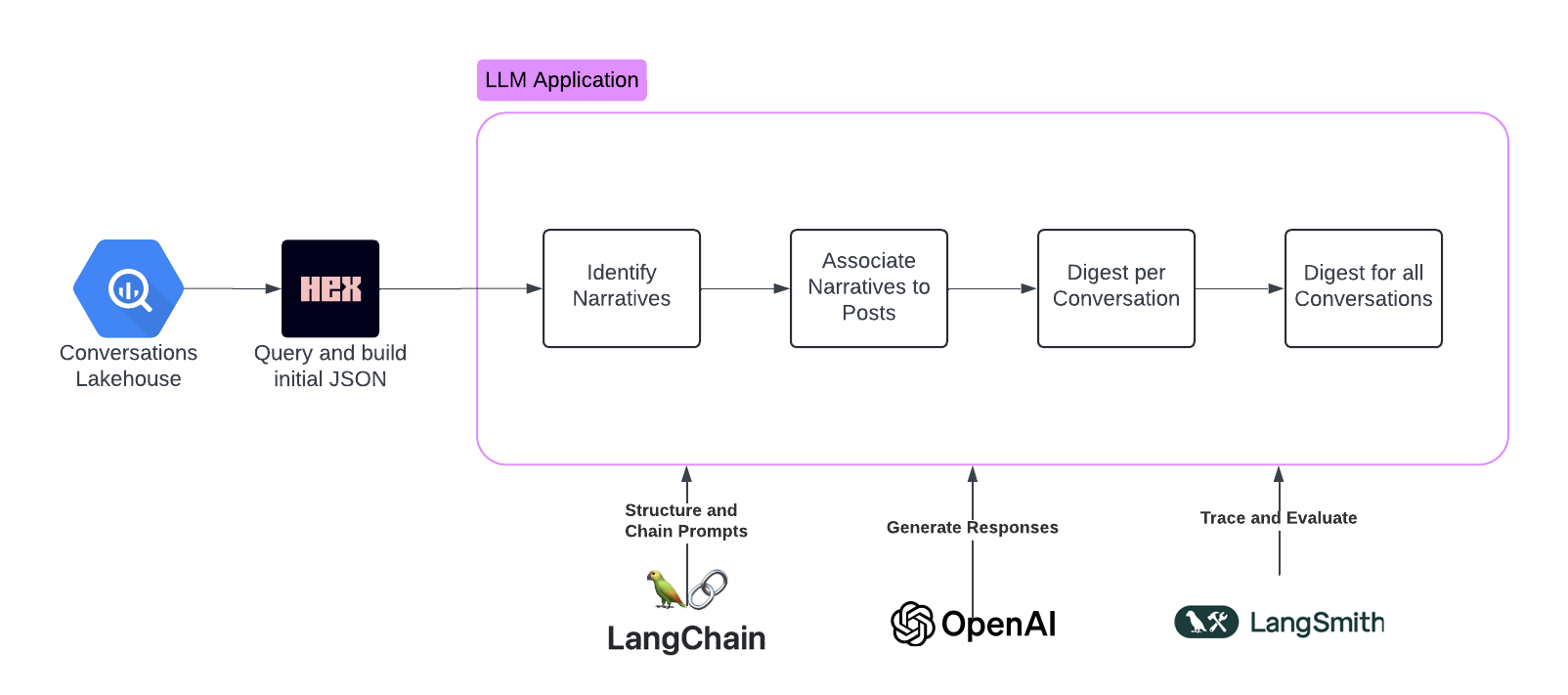
When we left off at the end of the previous post, we still had a lot to accomplish:
- Enforce the structure of outputs from Generative AI tasks.
- Evaluate the structure of the task's output.
- Finalizing the remaining components of the agent.
With so much to do, let's get started.
Enforce the Structure of Outputs From Generative AI Tasks
The output of generative AI tasks may be used by humans or other systems. As humans, we have the ability to understand LLM responses and organize their content in our minds. However, systems do not have this ability. They require input to be in a specific format that allows them to process the information and produce an output.
Fortunately, the LangChain framework includes features to enforce structure in a task's output
Parse Output into a Structured Class
For instance, our initial objective is to extract all the narratives present in a conversation. Because our structure is a bit more intricate than simply having a single element with several fields, we will define classes of objects. These will consist of our main object (Narratives) and its components (Narrative).
from typing import List
from langchain_core.pydantic_v1 import BaseModel, Field
class Narrative(BaseModel):
"""Information about a narrative."""
label: str = Field(description="A label to identify the identified narrative")
description: str = Field(description="A short description of the narrative")
class Narratives(BaseModel):
"""Identifying information about all narratives in a conversation."""
narratives: List[Narrative]
With the structure defined, we have the ability to insert specific instructions into our Generative AI task and then parse the generated output into an instance of our Narratives class.
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
# Components
model = ChatOpenAI(model="gpt-4")
parser = PydanticOutputParser(pydantic_object=Narratives)
# Prompt
system_template = """
# IDENTITY and PURPOSE
You are an expert at extracting narratives from conversations.
# STEPS
1. Ingest the json file which has conversations on climate change
2. Take your time to process all its entries
3. Parse all conversations and extract all narratives
4. Each narrative should have a label and a short description (5 to 10 words)
# OUTPUT INSTRUCTIONS
{format_instructions}
"""
prompt_template = ChatPromptTemplate.from_messages([
("system", system_template),
("human", "{text}"),
]).partial(format_instructions=parser.get_format_instructions())
# Task
chain = prompt_template | model | parser
Testing Out Our New Task
Let's invoke that chain.
output = chain.invoke({"text": conversation_filtered_json})
Let's check its type.
type(output)
__main__.Narratives
This is a sample of the object we get.
narratives=[Narrative(label='Climate Change Impact', description='Record-shattering high temperatures due to climate change'), Narrative(label='Scientist Distrust', description='Skepticism towards scientists and their studies'), ...]Let's convert this to a JSON object.
{
"narratives": [
{
"label": "Climate Change Impact",
"description": "Record-shattering high temperatures due to climate change"
},
{
"label": "Scientist Distrust",
"description": "Skepticism towards scientists and their studies"
},
...
]
}
When looking at this run in LangSmith, we can see the additional instructions that were passed to our LLM to enforce structure.
output:
messages:
- content: |
# IDENTITY and PURPOSE
You are an expert at extracting narratives from conversations.
# STEPS
1. Ingest the json file which has conversations on climate change
2. Take your time to process all its entries
3. Parse all conversations and extract all narratives
4. Each narrative should have a label and a short description (5 to 10 words)
# OUTPUT INSTRUCTIONS
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
``
{"description": "Identifying information about all narratives in a conversation.", "properties": {"narratives": {"title": "Narratives", "type": "array", "items": {"$ref": "#/definitions/Narrative"}}}, "required": ["narratives"], "definitions": {"Narrative": {"title": "Narrative", "description": "Information about a narrative.", "type": "object", "properties": {"label": {"title": "Label", "description": "A label to identify the identified narrative", "type": "string"}, "description": {"title": "Description", "description": "A short description of the narrative", "type": "string"}}, "required": ["label", "description"]}}}
``
additional_kwargs: {}
response_metadata: {}
type: system
- content: "[{\"conversation_natural_key\":1795461303563112576,\"posts\":[{\"post_natural_key\":1795461303563112576,\"post_creation_ts\":\"2024-05-28 14:25:07.000000 UTC\",\"post_text\":\"Over the past year of record-shattering warmth, the average person on Earth experienced 26 more days of abnormally high temperatures than they otherwise would have, were it not for human-induced climate change, scientists said Tuesday. https:\\/\\/t.co\\/RVI2ieLHYp\"},...]"
additional_kwargs: {}
response_metadata: {}
type: human
example: false
Evaluate the Structure of the Task's Output
We introduced LangChain's evaluators in the previous post. We will further use them here to validate that the output of our task conforms to the structure we want.
Remember that evaluations are performed on examples defined within a dataset. After running an evaluation, LangSmith will iterate over these examples, apply the task to them, store the output, and evaluate it against our tests.
For now, we need to assess if an output's schema conforms to an expected structure. We will use the JsonValidityEvaluator evaluator for that purpose.
from langchain.evaluation import JsonSchemaEvaluator, JsonValidityEvaluator
from langsmith.evaluation import evaluate, EvaluationResult
from langsmith.schemas import Run, Example
def extract_narratives_app(inputs):
output = chain.invoke({"text": conversation_filtered_json})
narratives_dict = output.dict()
narratives_json = json.dumps(narratives_dict, indent=4)
return {"output": narratives_json}
def is_valid_json(run: Run, example: Example) -> EvaluationResult:
evaluator = JsonValidityEvaluator()
# Get outputs
narratives = run.outputs.get("output")
# Evaluate structure
evaluation = evaluator.evaluate_strings(prediction=narratives)
# Check if the narratives is structured
return EvaluationResult(key="is_valid_json", score=evaluation["score"])
def is_valid_structure(run: Run, example: Example) -> EvaluationResult:
evaluator = JsonSchemaEvaluator()
# Get outputs
narratives = run.outputs.get("output")
schema = {
"type": "object",
"properties": {
"narratives": {
"type": "array",
"items": {
"type": "object",
"properties": {
"label": {"type": "string"},
"description": {"type": "string"}
},
"required": ["label", "description"]
}
}
},
"required": ["narratives"]
}
# Evaluate structure
evaluation = evaluator.evaluate_strings(
prediction=narratives,
reference=schema)
# Check if the narratives is structured
return EvaluationResult(key="is_valid_structure", score=evaluation["score"])
# Evaluators
evalulators = [is_valid_json, is_valid_structure]
dataset_name = "Conversations Analyzer - Narratives"
# Run
experiment_results = evaluate(
extract_narratives_app,
data=dataset_name,
evaluators=evalulators,
experiment_prefix="openai-gpt-4",
)
There's quite a lot happening here, so let's take it in steps.
Defining an App
LangSmith's evaluate method relies on the app as its central object.
def extract_narratives_app(inputs):
output = chain.invoke({"text": conversation_filtered_json})
narratives_dict = output.dict()
narratives_json = json.dumps(narratives_dict, indent=4)
return {"output": narratives_json}
The app invokes our chain (prompt template + model + parser), takes the output and converts it to a JSON object which we'll use to evaluate our structure.
Defining Evaluators
We define evaluators to assess if our output matches our structure. We use 2 evaluators: one to check if the output is a JSON object, and another to verify if it follows our Narratives structure.
def is_valid_json(run: Run, example: Example) -> EvaluationResult:
evaluator = JsonValidityEvaluator()
# Get outputs
narratives = run.outputs.get("output")
# Evaluate structure
evaluation = evaluator.evaluate_strings(prediction=narratives)
# Check if the narratives is structured
return EvaluationResult(key="is_valid_json", score=evaluation["score"])
def is_valid_structure(run: Run, example: Example) -> EvaluationResult:
evaluator = JsonSchemaEvaluator()
# Get outputs
narratives = run.outputs.get("output")
schema = {
"type": "object",
"properties": {
"narratives": {
"type": "array",
"items": {
"type": "object",
"properties": {
"label": {"type": "string"},
"description": {"type": "string"}
},
"required": ["label", "description"]
}
}
},
"required": ["narratives"]
}
# Evaluate structure
evaluation = evaluator.evaluate_strings(
prediction=narratives,
reference=schema)
# Check if the narratives is structured
return EvaluationResult(key="is_valid_structure", score=evaluation["score"])
Running Evaluators and Logging Results
Finally, we can test our app using the examples, evaluate its output, and log everything in LangSmith.
# Evaluators
evalulators = [is_valid_json, is_valid_structure]
dataset_name = "Conversations Analyzer - Narratives"
# Run
experiment_results = evaluate(
extract_narratives_app,
data=dataset_name,
evaluators=evalulators,
experiment_prefix="openai-gpt-4",
)
We ran two experiments:
- one with the correct object schema
- another one in which we changed the name of a field from "description" to "descriptions."
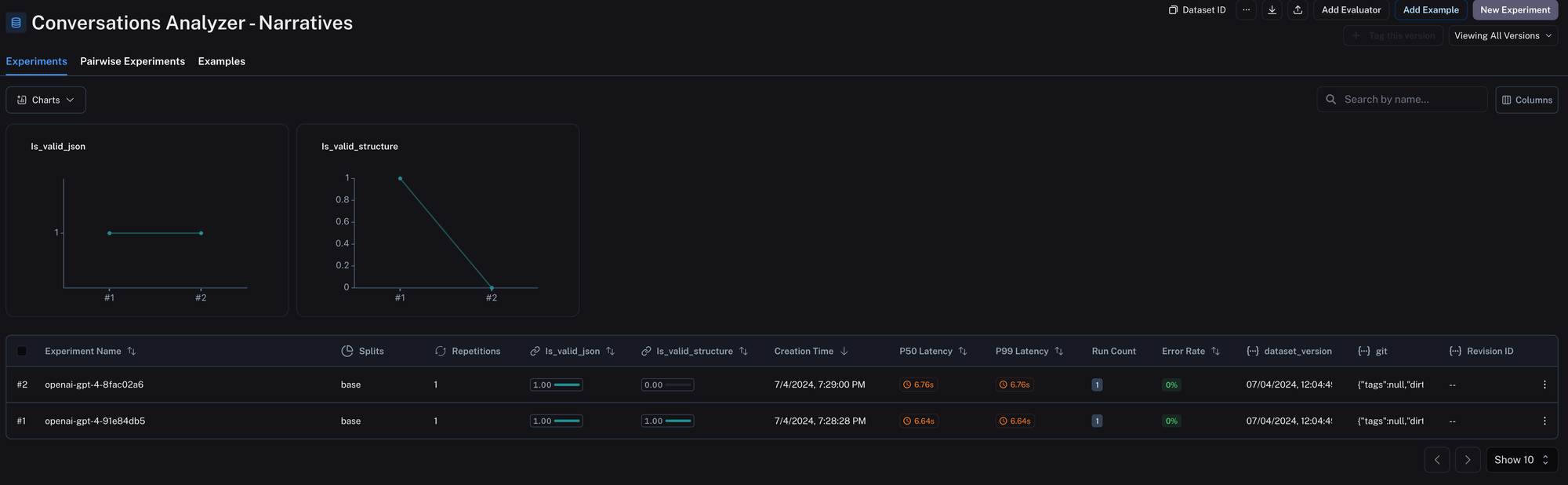
The first experiment successfully validated that the output of our Generative AI task was a JSON object and conformed to our schema, whereas the second experiment failed the "is_valid_structure" evaluation.
Finalizing the Remaining Components of the AI Agent
Now that we can efficiently define, structure, test, and trace our Generative AI tasks, we can work on the remaining tasks that will compose our AI agent. However, since this duplicates what we have already covered, let's skip ahead and focus on putting together our agent.
Running Our Agent
We are using Hex.tech to put all the pieces together.
We first have an Explorer section where we can browse the most active conversations and their associated posts.

We can then Select a conversation which we want our agent to analyze.
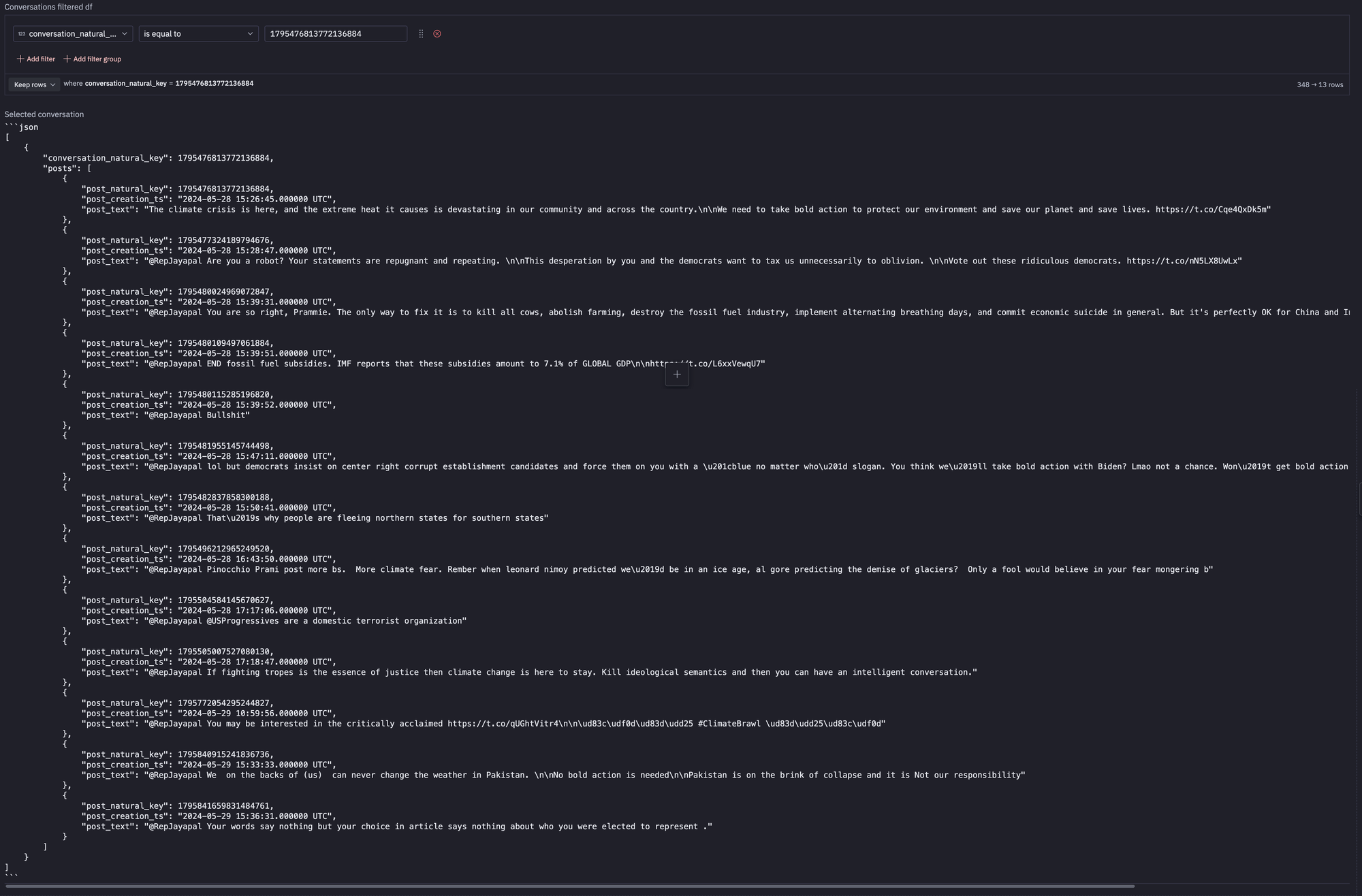
This is where our agent finally kicks in. It first take the conversation JSON object and extracts the main narratives being discussed.
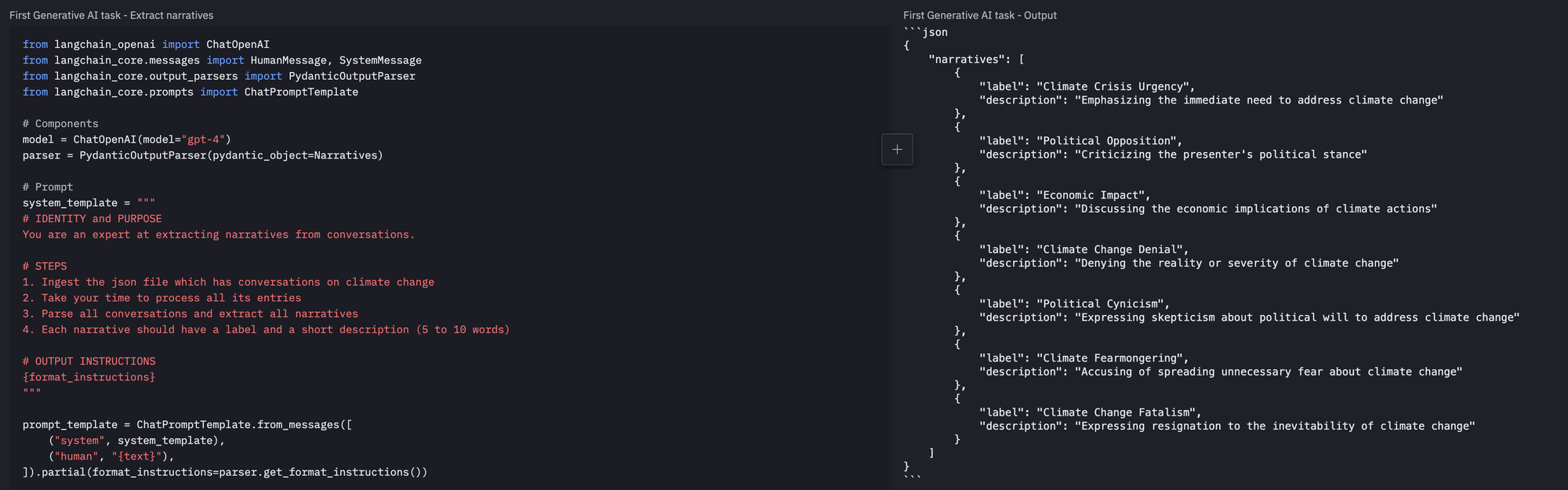
The agent then associates each post with the most appropriate narrative.
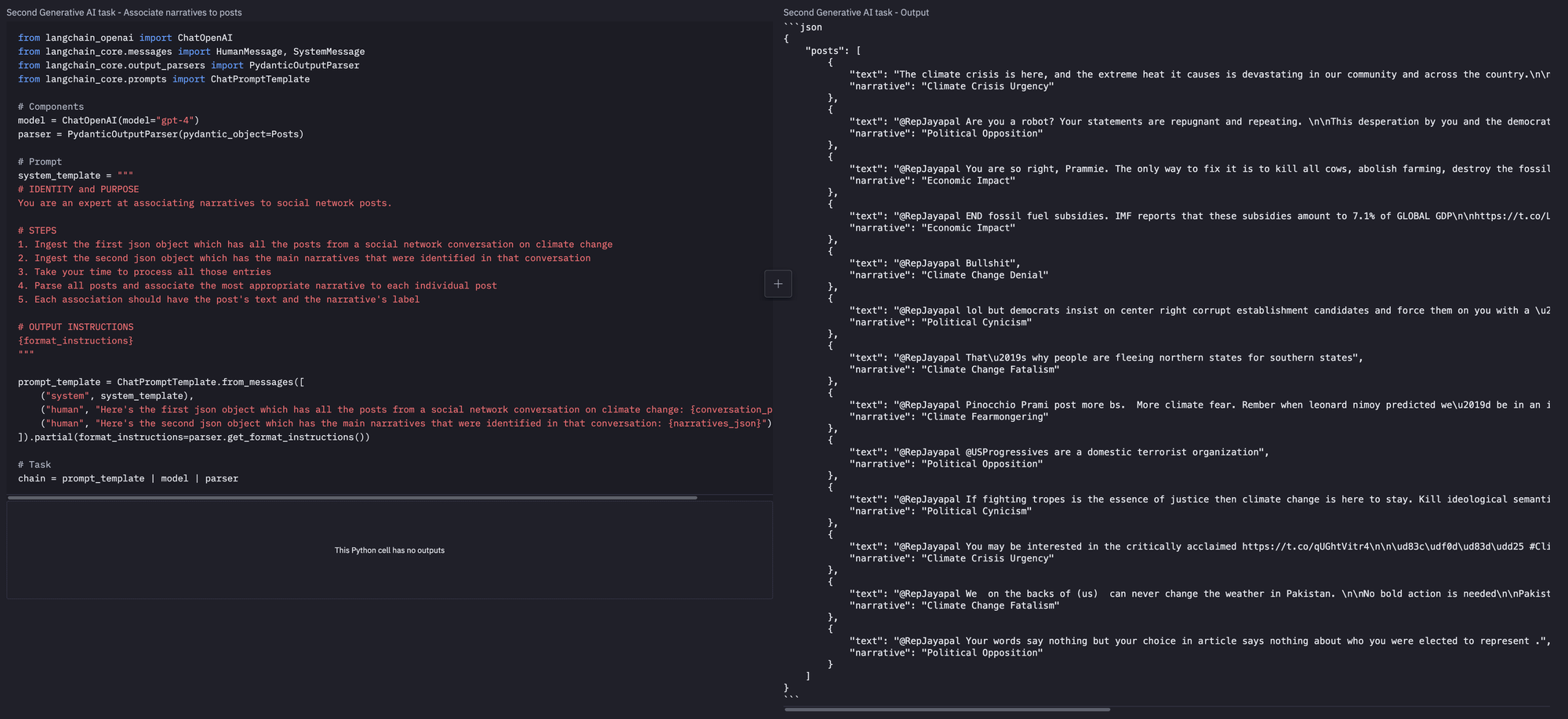
And finally, the agent summarizes the conversation.
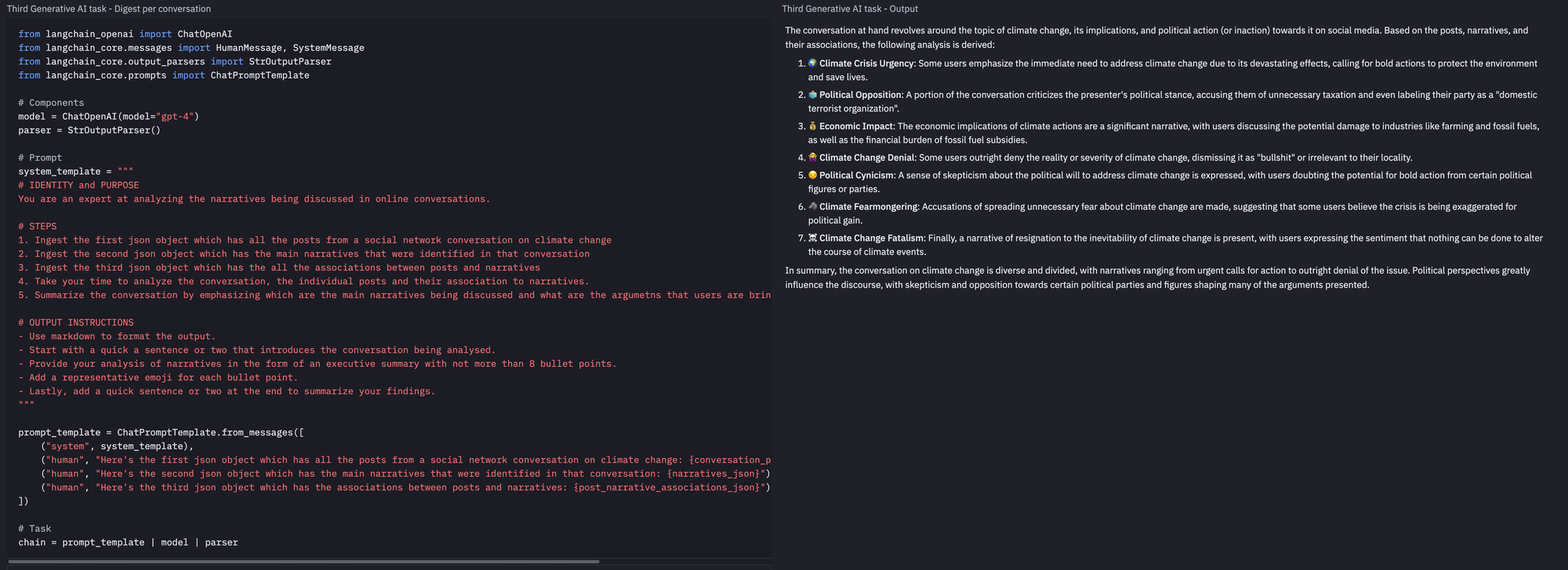
We could have added an extra task for our agent to handle multiple conversations as input and produce a single summary of all those discussions. However, for brevity, we will stop here.
Monitoring
When you execute your agent, LangSmith will be collecting the metadata for all LLM calls. This includes tracking usage, generated tokens, costs, and latency. This is particularly beneficial if you plan to make your agent accessible to the public.

Conclusion
While we have achieved significant milestones in developing and structuring our AI agent, there is always room for further refinement. Future enhancements could include handling multiple conversations simultaneously and optimizing performance. Nonetheless, our journey from experimenting with Ollama, Fabric, and OpenWebUI to developing a sophisticated AI agent has been a success. This series demonstrates the potential of structured generative AI in analyzing complex online discussions and providing meaningful insights.