Exploring the Climate Resilience Data Platform: A Survey of Its Assets
This post explores the Climate Resilience Data Platform, showcasing how it sources climate articles, tracks social conversations, and classifies narratives. A behind-the-scenes look at refining data products to reveal societal insights and advance the mission of RepublicOfData.io.
 Olivier Dupuis
—
—
23 min read min read
Olivier Dupuis
—
—
23 min read min read
Over the past months, I’ve iterated quickly to create a platform that captures climate-related conversations on social networks. I shared my journey and turned a blind eye to my accumulated tech debt. Or didn’t blink twice when confronted with suspicious data quality.
The last months might not have led to any breakthrough innovation worth reporting on, but they have been busy: refactoring the asset management system, enforcing stricter typed datasets, productionizing AI agents, and more.
I think it’s now worth taking a step back and examining the platform's data assets. We won’t dive deep into any story yet (I’ll save that for the next post). Instead, we’ll survey the material we now have.
This will be a deep dive into much metadata, so buckle up!
- Climate Resilience Data Platform: the data platform itself.
- Story notebooks: the notebooks to interact with the data.
- Damn Tool: a tool to interact with the platform’s assets.
🏛️ Design
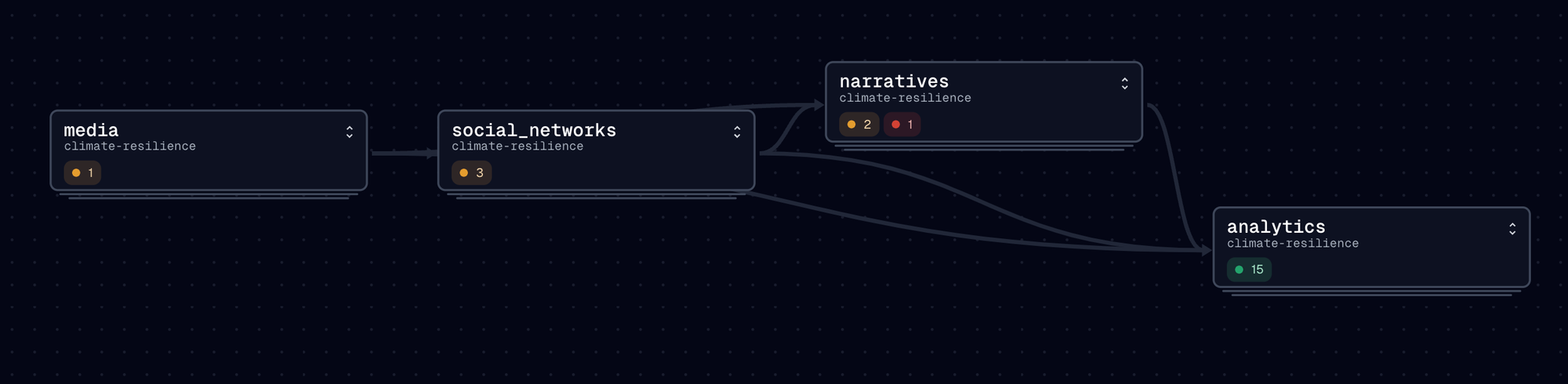
The platform is built around 4 key data products:
media: The climate-related articles being sourced.social_networks: The conversations that refer to the articles above.narratives: The classification of conversations and posts into discourse types and narratives.analytics: The dimensional representation of those assets for reporting purposes.
Here’s a complete list of assets produced by the platform.
import json
from damn_tool.ls import list_assets
result = list_assets(orchestrator='dagster', configs_dir="../.damn/")
data = json.loads(result)
organized_data = {}
for item in data["ls"]:
product, key = item.split("/", 1)
if product not in organized_data:
organized_data[product] = []
organized_data[product].append(key)
for product, keys in organized_data.items():
print(f"{product}:")
for key in keys:
print(f" - {key}")Listing assets using the DAMN tool.
analytics:
- int__media_articles
- int__social_network_conversations
- int__social_network_posts
- int__social_network_user_profiles
- media_articles_fct
- social_network_conversations_dim
- social_network_posts_fct
- social_network_user_profiles_dim
- stg__conversation_classifications
- stg__conversation_event_summaries
- stg__nytimes_articles
- stg__post_narrative_associations
- stg__user_geolocations
- stg__x_conversation_posts
- stg__x_conversations
media:
- nytimes_articles
narratives:
- conversation_classifications
- conversation_event_summary
- post_narrative_associations
social_networks:
- user_geolocations
- x_conversation_posts
- x_conversationsListing of assets from the Climate Resilience data platform.
📊 Data Assets
Let’s now dive into each of those assets.
Media Assets
For now, we are only monitoring the New York Times for climate-related articles.
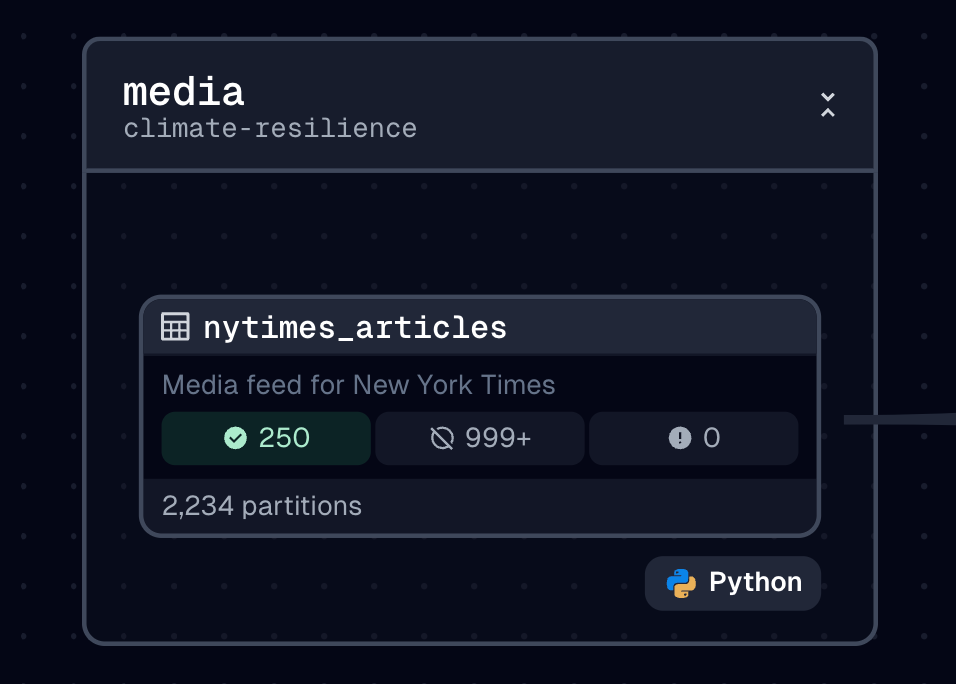
Let’s get a selection of the attributes from the media assets.
import json
from damn_tool.show import show_asset
result = show_asset('media/nytimes_articles', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract and print the desired attributes
asset_details = data["show"]
orchestrator_details = asset_details["From orchestrator"]
warehouse_details = asset_details["From data warehouse"]
# Combine attributes into a single string
output = (
f"- Description: {orchestrator_details['description']}\n"
f"- Compute kind: {orchestrator_details['computeKind']}\n"
f"- Is partitioned: {orchestrator_details['isPartitioned']}\n"
f"- Table type: {warehouse_details['table_type']}\n"
f"- Table schema: {warehouse_details['table_schema']}\n"
f"- Created: {warehouse_details['created']}"
)
# Print the final string
print(output)Getting attributes from the nytimes_articles asset.
- Description: Media feed for New York Times
- Compute kind: python
- Is partitioned: True
- Table type: BASE TABLE
- Table schema: media
- Created: 2024-12-12T18:44:11.473000+00:00Attributes from the nytimes_articles asset.
And some metrics:
import json
from damn_tool.metrics import asset_metrics
result = asset_metrics('media/nytimes_articles', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract relevant metrics
orchestrator_metrics = data["metrics"]["From orchestrator"]
dw_metrics = data["metrics"]["From data warehouse"]
# Combine metrics into a single string
output = (
f"- Row count: {dw_metrics['row_count']}\n"
f"- Size: {dw_metrics['bytes']}\n"
f"- Last run id: {orchestrator_metrics['run_id']}\n"
f"- Last run status: {orchestrator_metrics['status']}\n"
f"- Last start time: {orchestrator_metrics['start_time']}\n"
f"- Last end time: {orchestrator_metrics['end_time']}\n"
f"- Number of partitions: {orchestrator_metrics['num_partitions']}\n"
f"- Number of partitions materialized: {orchestrator_metrics['num_materialized']}\n"
f"- Number of failed partitions: {orchestrator_metrics['num_failed']}"
)
# Print the final string
print(output)Getting metrics from the nytimes_articles asset.
- Row count: 894
- Size: 649.96 KB
- Last run id: e6cf5f89-f14d-4623-9496-82b52efe79d1
- Last run status: SUCCESS
- Last start time: 2024-12-24 10:01:45
- Last end time: 2024-12-24 10:01:54
- Number of partitions: 2275
- Number of partitions materialized: 291
- Number of failed partitions: 0Metrics from the nytimes_articles asset.
Let’s pull the data from this asset:
import pyarrow.feather as feather
from google.cloud import bigquery
# Construct a BigQuery client object.
client = bigquery.Client()
query = """
select *
from `phonic-biplane-420020.media.nytimes_articles`
order by published_ts desc
limit 5"""
# Make an API request.
query_job = client.query(query)
# Wait for the job to complete.
articles_df = query_job.result().to_dataframe()
# Write the DataFrame to a Feather file
feather_file = "data/articles.feather"
feather.write_feather(articles_df, feather_file)
# Pass the file path to the global namespace
globals()['articles_feather'] = feather_fileGetting a data sample from the nytimes_articles asset.
library(arrow)
# Read the Feather file
feather_file <- reticulate::py$articles_feather
# Read the Feather file
articles_df <- read_feather(feather_file)
# Display the table
kable(
articles_df,
format = "html",
escape = TRUE
)Displaying data sample from the nytimes_articles asset.
| MEDIA | ID | TITLE | LINK | SUMMARY | AUTHOR | TAGS | MEDIAS | PUBLISHED_TS |
|---|---|---|---|---|---|---|---|---|
| nytimes | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | Trump’s Wish to Control Greenland and Panama Canal: Not a Joke This Time | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | In recent days the president-elect has called for asserting U.S. control over the Panama Canal and Greenland, showing that his “America First” philosophy has an expansionist dimension. | David E. Sanger and Lisa Friedman | United States International Relations,United States Politics and Government,Trump, Donald J,Greenland,Panama Canal and Canal Zone,Presidential Election of 2024,Global Warming,Metals and Minerals,Ships and Shipping,Egede, Mute B,Arctic Regions,Denmark,Panama | https://static01.nyt.com/images/2024/12/23/multimedia/23DC-TRUMP-mpcg/23DC-TRUMP-mpcg-mediumSquareAt3X.jpg | 2024-12-23 22:08:12 |
| nytimes | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | Trump’s Wish to Control Greenland and Panama Canal: Not a Joke This Time | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | In recent days the president-elect has called for asserting U.S. control over the Panama Canal and Greenland, showing that his “America First” philosophy has an expansionist dimension. | David E. Sanger and Lisa Friedman | United States International Relations,United States Politics and Government,Trump, Donald J,Greenland,Panama Canal and Canal Zone,Presidential Election of 2024,Global Warming,Metals and Minerals,Ships and Shipping,Egede, Mute B,Arctic Regions,Denmark,Panama | https://static01.nyt.com/images/2024/12/23/multimedia/23DC-TRUMP-mpcg/23DC-TRUMP-mpcg-mediumSquareAt3X.jpg | 2024-12-23 21:08:14 |
| nytimes | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | Trump’s Wish to Control Greenland and Panama Canal: Not a Joke This Time | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | In recent days the president-elect has called for asserting U.S. control over the Panama Canal and Greenland, showing that his “America First” philosophy has an expansionist dimension. | David E. Sanger and Lisa Friedman | United States International Relations,United States Politics and Government,Trump, Donald J,Greenland,Panama Canal and Canal Zone,Presidential Election of 2024,Global Warming,Metals and Minerals,Ships and Shipping,Egede, Mute B,Arctic Regions,Denmark,Panama | https://static01.nyt.com/images/2024/12/23/multimedia/23DC-TRUMP-mpcg/23DC-TRUMP-mpcg-mediumSquareAt3X.jpg | 2024-12-23 18:20:01 |
| nytimes | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | Trump’s Wish to Control Greenland and Panama Canal: Not a Joke This Time | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | In recent days the president-elect has called for asserting U.S. control over the Panama Canal and Greenland, showing that his “America First” philosophy has an expansionist dimension. | David E. Sanger and Lisa Friedman | United States International Relations,United States Politics and Government,Trump, Donald J,Greenland,Panama Canal and Canal Zone,Presidential Election of 2024,Global Warming,Metals and Minerals,Ships and Shipping,Egede, Mute B,Arctic Regions,Denmark,Panama | https://static01.nyt.com/images/2024/12/23/multimedia/23DC-TRUMP-mpcg/23DC-TRUMP-mpcg-mediumSquareAt3X.jpg | 2024-12-23 17:10:55 |
| nytimes | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | Trump’s Wish to Control Greenland and Panama Canal: Not a Joke This Time | https://www.nytimes.com/2024/12/23/us/politics/trump-greenland-panama-canal.html | In recent days the president-elect has called for asserting U.S. control over the Panama Canal and Greenland, showing that his “America First” philosophy has an expansionist dimension. | David E. Sanger and Lisa Friedman | United States International Relations,United States Politics and Government,Trump, Donald J,Greenland,Panama Canal and Canal Zone,Presidential Election of 2024,Global Warming,Metals and Minerals,Ships and Shipping,Egede, Mute B,Arctic Regions,Denmark,Panama | https://static01.nyt.com/images/2024/12/23/multimedia/23DC-TRUMP-mpcg/23DC-TRUMP-mpcg-mediumSquareAt3X.jpg | 2024-12-23 16:20:18 |
Articles are the foundation of the platform. Once climate-related articles are pulled, the platform monitors social networks and capture conversations that refer to them.
Social Networks Assets
We then monitor conversations on social networks (for now, only X) that refer to the articles sourced.
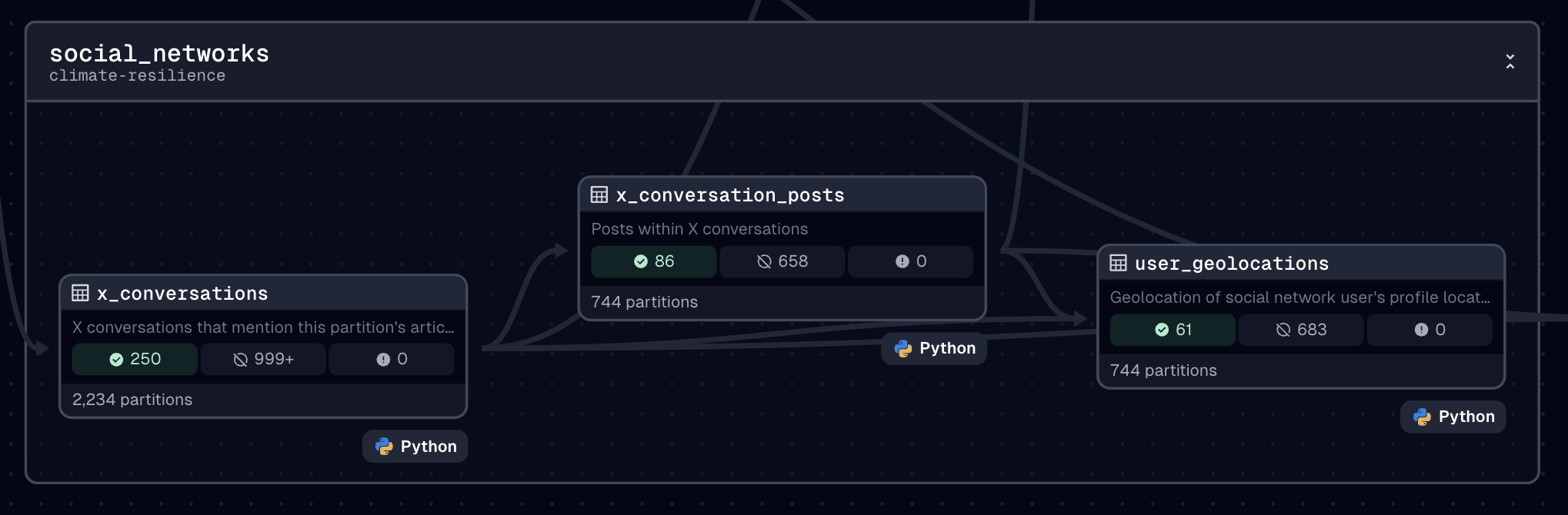
Let’s now get some details on conversations that occur on X.
import json
from damn_tool.show import show_asset
result = show_asset('social_networks/x_conversations', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract and print the desired attributes
asset_details = data["show"]
orchestrator_details = asset_details["From orchestrator"]
warehouse_details = asset_details["From data warehouse"]
# Combine attributes into a single string
output = (
f"- Description: {orchestrator_details['description']}\n"
f"- Compute kind: {orchestrator_details['computeKind']}\n"
f"- Is partitioned: {orchestrator_details['isPartitioned']}\n"
f"- Table type: {warehouse_details['table_type']}\n"
f"- Table schema: {warehouse_details['table_schema']}\n"
f"- Created: {warehouse_details['created']}"
)
# Print the final string
print(output)Getting attributes from the x_conversations asset.
- Description: X conversations that mention this partition's article
- Compute kind: python
- Is partitioned: True
- Table type: BASE TABLE
- Table schema: social_networks
- Created: 2024-12-12T18:44:47.015000+00:00Attributes from the x_conversations asset.
Some metrics:
import json
from damn_tool.metrics import asset_metrics
result = asset_metrics('social_networks/x_conversations', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract relevant metrics
orchestrator_metrics = data["metrics"]["From orchestrator"]
dw_metrics = data["metrics"]["From data warehouse"]
# Combine metrics into a single string
output = (
f"- Row count: {dw_metrics['row_count']}\n"
f"- Size: {dw_metrics['bytes']}\n"
f"- Last run id: {orchestrator_metrics['run_id']}\n"
f"- Last run status: {orchestrator_metrics['status']}\n"
f"- Last start time: {orchestrator_metrics['start_time']}\n"
f"- Last end time: {orchestrator_metrics['end_time']}\n"
f"- Number of partitions: {orchestrator_metrics['num_partitions']}\n"
f"- Number of partitions materialized: {orchestrator_metrics['num_materialized']}\n"
f"- Number of failed partitions: {orchestrator_metrics['num_failed']}"
)
# Print the final string
print(output)Getting metrics from the x_conversations asset.
- Row count: 8203
- Size: 5.51 MB
- Last run id: 84dd166d-a39c-4574-9b3d-f578b2cb9de3
- Last run status: SUCCESS
- Last start time: 2024-12-24 10:11:44
- Last end time: 2024-12-24 10:11:51
- Number of partitions: 2275
- Number of partitions materialized: 291
- Number of failed partitions: 0Metrics from the x_conversations asset.
Let’s pull some conversations:
from google.cloud import bigquery
import pyarrow.feather as feather
# Construct a BigQuery client object.
client = bigquery.Client()
query = """
select * except (tweet_public_metrics, author_public_metrics)
from `social_networks.x_conversations`
limit 5"""
# Make an API request.
query_job = client.query(query)
# Wait for the job to complete.
conversations_df = query_job.result().to_dataframe()
# Write the DataFrame to a Feather file
feather_file = "data/x_conversations.feather"
feather.write_feather(conversations_df, feather_file)
# Pass the file path to the global namespace
globals()['x_conversations_feather'] = feather_fileGetting a data sample from the x_conversations asset.
library(arrow)
library(dplyr)
# Read the Feather file
feather_file <- reticulate::py$x_conversations_feather
# Read the Feather file
conversations_df <- read_feather(feather_file)
conversations_df <- conversations_df %>%
mutate(
TWEET_TEXT = substr(TWEET_TEXT, 1, 50)
)
# Display the table
kable(
conversations_df,
format = "html", # Ensures better rendering in Quarto
escape = TRUE
)Displaying data sample from the x_conversations asset.
| ARTICLE_URL | TWEET_ID | TWEET_CREATED_AT | TWEET_CONVERSATION_ID | TWEET_TEXT | AUTHOR_ID | AUTHOR_USERNAME | AUTHOR_LOCATION | AUTHOR_DESCRIPTION | AUTHOR_CREATED_AT | PARTITION_HOUR_UTC_TS | RECORD_LOADING_TS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| https://www.nytimes.com/2024/12/20/well/cold-deaths-health.html | 1870194128631541938 | 2024-12-20 14:46:41 | 1870194128631541938 | "Even though we are in this warming world, cold-re | 759094814897999873 | SmithBIDMC | Boston, MA | Official account of the Richard A. and Susan F. Smith Center for Outcomes Research in Cardiology @BIDMChealth @BIDMCCVI. RTs ≠ Endorsements | 2016-07-29 14:34:41 | 2024-12-20 14:00:00 | 2024-12-20 15:11:47 |
| https://www.nytimes.com/2024/12/20/well/cold-deaths-health.html | 1870186321907724544 | 2024-12-20 14:15:40 | 1870186321907724544 | Check out @nytimes piece by @emilyschmall on our @ | 860518198277545985 | rkwadhera | Boston, MA | Associate Professor @HarvardMed | Cardiologist @BIDMCHealth | Associate Director @SmithBIDMC | Health Policy and Outcomes Research | | 2017-05-05 11:35:00 | 2024-12-20 14:00:00 | 2024-12-20 15:11:47 |
| https://www.nytimes.com/2024/12/20/well/cold-deaths-health.html | 1870188986104254654 | 2024-12-20 14:26:15 | 1870188986104254654 | Try North America! 🌎 https://t.co/JgBZQUSMYR | 879378417694670848 | handsoitgoes | Quebec??=🇨🇦 or 🇫🇷 ?? | "🇨🇦/🇺🇸 border kid. Ex-M. SJTO/TJSO (Social Justice Tribunals of Ontario/Tribunaux de justice sociale de l'Ontario), MLS, BA McGill "Anthroapology" | 2017-06-26 12:38:47 | 2024-12-20 14:00:00 | 2024-12-20 15:11:47 |
| https://www.nytimes.com/2024/12/20/well/cold-deaths-health.html | 1870304020801237067 | 2024-12-20 22:03:21 | 1870304020801237067 | pretty sure it's the homelessness above all https: | 1034174877488570370 | jhv85 | Brooklyn, NY | Writer/researcher specializing in American political development, political economy, party systems and ideology, social democracy. Columnist @compactmag_ | 2018-08-27 16:24:39 | 2024-12-20 22:00:00 | 2024-12-20 23:11:37 |
| https://www.nytimes.com/2024/12/20/well/cold-deaths-health.html | 1870328626916528572 | 2024-12-20 23:41:08 | 1870328626916528572 | #NYT1000本斬り 1428/2000 More People Are Now Dying Fr | 842975270168477696 | carina38925315 | 英語を教えて30年以上。今年は日本語教育能力検定試験と日本語教員試験受験。検定試験のみ合格。日本語教師として働く道を模索中。教員試験は来年合格したい。ハングル、イタリア語も勉強中。英検1級、英語通訳案内士、TOEICLR満点SW180/200 https://t.co/k9jjQFhk4o | 2017-03-18 01:45:40 | 2024-12-20 23:00:00 | 2024-12-21 00:11:44 |
We then continue monitoring those conversations for 24 hours to capture all their posts. Here are some details on that asset:
import json
from damn_tool.show import show_asset
result = show_asset('social_networks/x_conversation_posts', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract and print the desired attributes
asset_details = data["show"]
orchestrator_details = asset_details["From orchestrator"]
warehouse_details = asset_details["From data warehouse"]
# Combine attributes into a single string
output = (
f"- Description: {orchestrator_details['description']}\n"
f"- Compute kind: {orchestrator_details['computeKind']}\n"
f"- Is partitioned: {orchestrator_details['isPartitioned']}\n"
f"- Table type: {warehouse_details['table_type']}\n"
f"- Table schema: {warehouse_details['table_schema']}\n"
f"- Created: {warehouse_details['created']}"
)
# Print the final string
print(output)Getting attributes from the x_conversation_posts asset.
- Description: Posts within X conversations
- Compute kind: python
- Is partitioned: True
- Table type: BASE TABLE
- Table schema: social_networks
- Created: 2024-12-12T18:44:28.374000+00:00Attributes from the x_conversation_posts asset.
Some metrics:
import json
from damn_tool.metrics import asset_metrics
result = asset_metrics('social_networks/x_conversation_posts', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract relevant metrics
orchestrator_metrics = data["metrics"]["From orchestrator"]
dw_metrics = data["metrics"]["From data warehouse"]
# Combine metrics into a single string
output = (
f"- Row count: {dw_metrics['row_count']}\n"
f"- Size: {dw_metrics['bytes']}\n"
f"- Last run id: {orchestrator_metrics['run_id']}\n"
f"- Last run status: {orchestrator_metrics['status']}\n"
f"- Last start time: {orchestrator_metrics['start_time']}\n"
f"- Last end time: {orchestrator_metrics['end_time']}\n"
f"- Number of partitions: {orchestrator_metrics['num_partitions']}\n"
f"- Number of partitions materialized: {orchestrator_metrics['num_materialized']}\n"
f"- Number of failed partitions: {orchestrator_metrics['num_failed']}"
)
# Print the final string
print(output)Getting metrics from the x_conversation_posts asset.
- Row count: 4415
- Size: 2.38 MB
- Last run id: 63a9fe77-8ed3-4c77-b59c-b74efe609713
- Last run status: SUCCESS
- Last start time: 2024-12-24 10:21:45
- Last end time: 2024-12-24 10:21:57
- Number of partitions: 758
- Number of partitions materialized: 100
- Number of failed partitions: 0Metrics from the x_conversation_posts asset.
Let’s get some posts:
from google.cloud import bigquery
import pyarrow.feather as feather
# Construct a BigQuery client object.
client = bigquery.Client()
query = """
select * except (article_url, tweet_public_metrics, author_public_metrics)
from `social_networks.x_conversation_posts`
limit 5"""
# Make an API request.
query_job = client.query(query)
# Wait for the job to complete.
conversation_posts_df = query_job.result().to_dataframe()
# Write the DataFrame to a Feather file
feather_file = "data/x_conversation_posts.feather"
feather.write_feather(conversation_posts_df, feather_file)
# Pass the file path to the global namespace
globals()['x_conversation_posts_feather'] = feather_fileGetting a data sample from the x_conversation_posts asset.
library(arrow)
library(dplyr)
# Read the Feather file
feather_file <- reticulate::py$x_conversation_posts_feather
# Read the Feather file
conversation_posts_df <- read_feather(feather_file)
conversation_posts_df <- conversation_posts_df %>%
mutate(
TWEET_TEXT = substr(TWEET_TEXT, 1, 50)
)
# Display the table
kable(
conversation_posts_df,
format = "html", # Ensures better rendering in Quarto
escape = TRUE
)Displaying the data sample from the x_conversation_posts asset.
| TWEET_ID | TWEET_CREATED_AT | TWEET_CONVERSATION_ID | TWEET_TEXT | AUTHOR_ID | AUTHOR_USERNAME | AUTHOR_LOCATION | AUTHOR_DESCRIPTION | AUTHOR_CREATED_AT | PARTITION_HOUR_UTC_TS | RECORD_LOADING_TS |
|---|---|---|---|---|---|---|---|---|---|---|
| 1871177534823383120 | 2024-12-23 07:54:23 | 1871176675834417432 | @Matthuber78 They are just anti-progress. Unless t | 199430225 | HibbertMatthew | Tavistock, Devon | Renegade-redhead soixante-sixard. Broadly Liberal but I like boundaries. Blog a bit. | 2010-10-06 17:09:24 | 2024-12-23 07:00:00 | 2024-12-23 13:21:37 |
| 1871178666358501848 | 2024-12-23 07:58:53 | 1871176675834417432 | @collectifission Regardless of how you model the f | 352833079 | Matthuber78 | Syracuse, NY | Geographer, Lifeblood (2013) @UMinnPress, Climate Change as Class War (2022) @VersoBooks https://t.co/OgdpkbYLz3 | 2011-08-11 00:08:33 | 2024-12-23 07:00:00 | 2024-12-23 13:21:37 |
| 1871182808481476922 | 2024-12-23 08:15:21 | 1871176675834417432 | @Matthuber78 Grinding up olivine is possibly the b | 1483186552587132932 | collectifission | All about energy and what that means for people, in relation with the rest of the world. With technology we can all live well, with room for nature to flourish. | 2022-01-17 16:17:24 | 2024-12-23 07:00:00 | 2024-12-23 13:21:37 | |
| 1871177492033372210 | 2024-12-23 07:54:13 | 1871176675834417432 | @Matthuber78 Honestly though: I know the IPCC mode | 1483186552587132932 | collectifission | All about energy and what that means for people, in relation with the rest of the world. With technology we can all live well, with room for nature to flourish. | 2022-01-17 16:17:24 | 2024-12-23 07:00:00 | 2024-12-23 13:21:37 | |
| 1871297366130934184 | 2024-12-23 15:50:33 | 1871287900257808710 | @mzjacobson @nytimes Carbon capture can reduce emi | 1574113788344664064 | ClimateSageO | Amman | تحويل سياسة المناخ إلى ممارسة #محارب_المناخ | 2022-09-25 15:09:08 | 2024-12-23 13:00:00 | 2024-12-23 19:21:43 |
Finally, we are geolocating the users that are part of those conversations. Some details:
import json
from damn_tool.show import show_asset
result = show_asset('social_networks/user_geolocations', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract and print the desired attributes
asset_details = data["show"]
orchestrator_details = asset_details["From orchestrator"]
warehouse_details = asset_details["From data warehouse"]
# Combine attributes into a single string
output = (
f"- Description: {orchestrator_details['description']}\n"
f"- Compute kind: {orchestrator_details['computeKind']}\n"
f"- Is partitioned: {orchestrator_details['isPartitioned']}\n"
f"- Table type: {warehouse_details['table_type']}\n"
f"- Table schema: {warehouse_details['table_schema']}\n"
f"- Created: {warehouse_details['created']}"
)
# Print the final string
print(output)Getting attributes from the `user_geolocations` asset.
- Description: Geolocation of social network user's profile location
- Compute kind: python
- Is partitioned: True
- Table type: BASE TABLE
- Table schema: social_networks
- Created: 2024-12-12T18:46:22.036000+00:00Attributes from the `user_geolocations` asset.
And some metrics:
import json
from damn_tool.metrics import asset_metrics
result = asset_metrics('social_networks/user_geolocations', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract relevant metrics
orchestrator_metrics = data["metrics"]["From orchestrator"]
dw_metrics = data["metrics"]["From data warehouse"]
# Combine metrics into a single string
output = (
f"- Row count: {dw_metrics['row_count']}\n"
f"- Size: {dw_metrics['bytes']}\n"
f"- Last run id: {orchestrator_metrics['run_id']}\n"
f"- Last run status: {orchestrator_metrics['status']}\n"
f"- Last start time: {orchestrator_metrics['start_time']}\n"
f"- Last end time: {orchestrator_metrics['end_time']}\n"
f"- Number of partitions: {orchestrator_metrics['num_partitions']}\n"
f"- Number of partitions materialized: {orchestrator_metrics['num_materialized']}\n"
f"- Number of failed partitions: {orchestrator_metrics['num_failed']}"
)
# Print the final string
print(output)Getting metrics from the `user_geolocations` asset.
- Row count: 4853
- Size: 523.74 KB
- Last run id: 63a9fe77-8ed3-4c77-b59c-b74efe609713
- Last run status: SUCCESS
- Last start time: 2024-12-24 10:22:06
- Last end time: 2024-12-24 10:22:21
- Number of partitions: 758
- Number of partitions materialized: 74
- Number of failed partitions: 0Metrics from the `user_geolocations` asset.
Let’s get some geolocated user records:
from google.cloud import bigquery
import pyarrow.feather as feather
# Construct a BigQuery client object.
client = bigquery.Client()
query = """
select * from `social_networks.user_geolocations`
order by geolocation_ts desc
limit 5"""
# Make an API request.
query_job = client.query(query)
# Wait for the job to complete.
user_geolocations_df = query_job.result().to_dataframe()
# Write the DataFrame to a Feather file
feather_file = "data/user_geolocations.feather"
feather.write_feather(user_geolocations_df, feather_file)
# Pass the file path to the global namespace
globals()['user_geolocations_feather'] = feather_fileGetting a data sample from the `user_geolocations` asset.
library(arrow)
# Read the Feather file
feather_file <- reticulate::py$user_geolocations_feather
# Read the Feather file
user_geolocations_df <- read_feather(feather_file)
# Display the table
kable(
user_geolocations_df,
format = "html", # Ensures better rendering in Quarto
escape = TRUE
)Displaying the data sample from the `user_geolocations` asset.
| SOCIAL_NETWORK_PROFILE_ID | SOCIAL_NETWORK_PROFILE_USERNAME | LOCATION_ORDER | LOCATION | COUNTRYNAME | COUNTRYCODE | ADMINNAME1 | ADMINCODE1 | LATITUDE | LONGITUDE | GEOLOCATION_TS | PARTITION_HOUR_UTC_TS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1478403674569428998 | babsi202 | 0 | Netherlands | The Netherlands | NL | 00 | 52.25 | 5.75 | 2024-12-24 10:22:13 | 2024-12-24 04:00:00 | |
| 404992844 | TomBauser | 0 | Frankfurt | Germany | DE | Hesse | 05 | 50.11552 | 8.68417 | 2024-12-24 10:22:13 | 2024-12-24 04:00:00 |
| 903288533259083778 | DemProud | 0 | United States | -14.60485 | -57.65625 | 2024-12-24 10:22:12 | 2024-12-24 04:00:00 | ||||
| 520658313 | CharlesHAllison | 0 | New York City | United States | US | New York | NY | 40.71427 | -74.00597 | 2024-12-24 10:22:12 | 2024-12-24 04:00:00 |
| 2786988640 | EricLebedel | 0 | Paris | France | FR | Île-de-France | 11 | 48.85341 | 2.3488 | 2024-12-24 10:22:11 | 2024-12-24 04:00:00 |
Narratives Assets
Now that we have the conversations and posts, we classify them into narratives and discourse types.
- Blog post on how I’m orchestrating AI agents
- A deep dive webinar I’ve done on the topic with the good folks at Dagster
- An agent’s definition in the platform’s codebase
- The agent’s invocation in the platform’s codebase
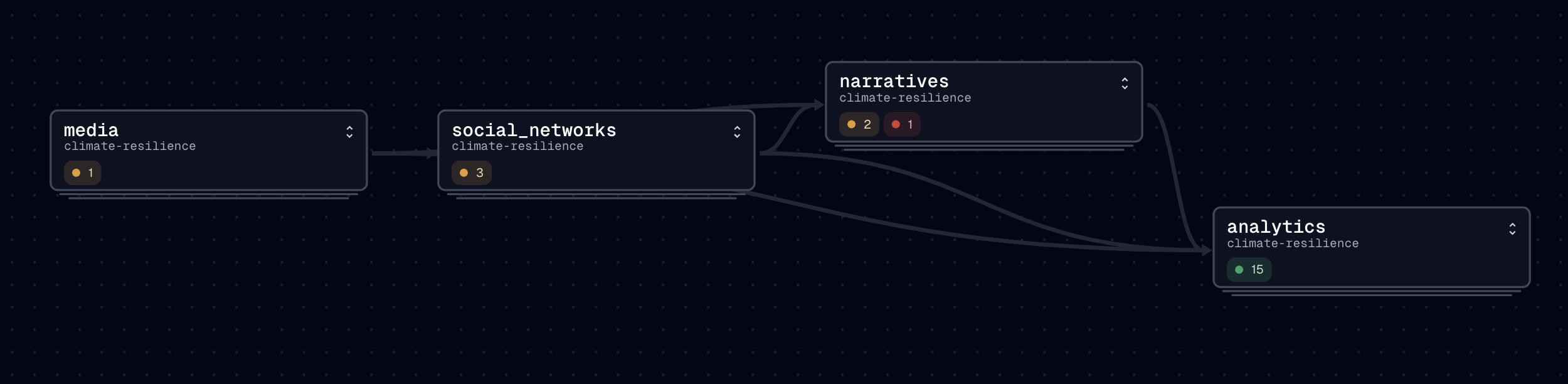
Let’s first have a look at the lineage between those narratives assets:
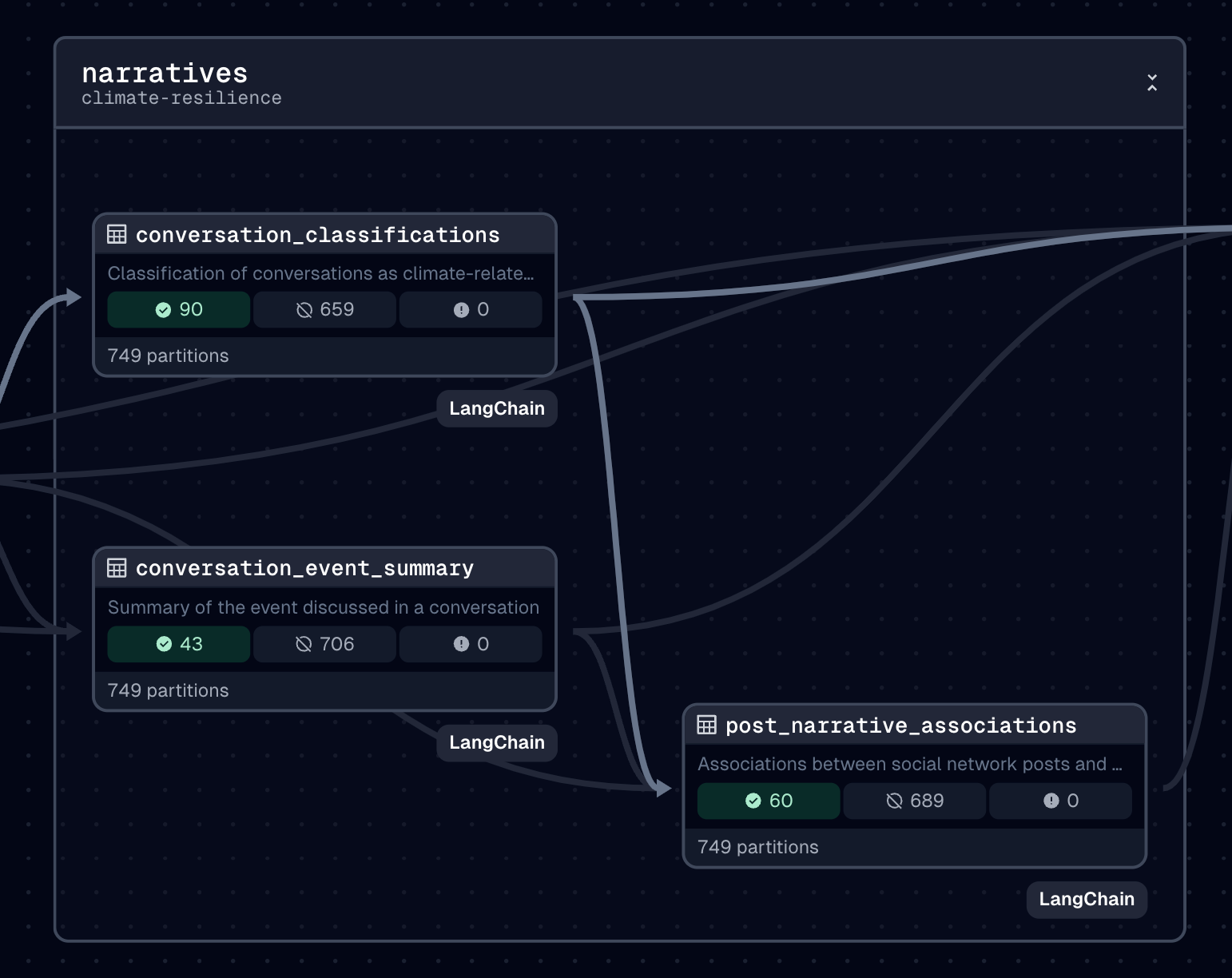
We start by classifying the conversations as to whether or not they discuss climate-related topics. Let’s see some attributes:
import json
from damn_tool.show import show_asset
result = show_asset('narratives/conversation_classifications', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract and print the desired attributes
asset_details = data["show"]
orchestrator_details = asset_details["From orchestrator"]
warehouse_details = asset_details["From data warehouse"]
# Combine attributes into a single string
output = (
f"- Description: {orchestrator_details['description']}\n"
f"- Compute kind: {orchestrator_details['computeKind']}\n"
f"- Is partitioned: {orchestrator_details['isPartitioned']}\n"
f"- Table type: {warehouse_details['table_type']}\n"
f"- Table schema: {warehouse_details['table_schema']}\n"
f"- Created: {warehouse_details['created']}"
)
# Print the final string
print(output)Getting attributes from the `conversation_classifications` asset.
- Description: Classification of conversations as climate-related or not
- Compute kind: LangChain
- Is partitioned: True
- Table type: BASE TABLE
- Table schema: narratives
- Created: 2024-12-12T18:45:28.708000+00:00Attributes from the `conversation_classifications` asset.
Let’s also have a look at some of its metrics:
import json
from damn_tool.metrics import asset_metrics
result = asset_metrics('narratives/conversation_classifications', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract relevant metrics
orchestrator_metrics = data["metrics"]["From orchestrator"]
dw_metrics = data["metrics"]["From data warehouse"]
# Combine metrics into a single string
output = (
f"- Row count: {dw_metrics['row_count']}\n"
f"- Size: {dw_metrics['bytes']}\n"
f"- Last run id: {orchestrator_metrics['run_id']}\n"
f"- Last run status: {orchestrator_metrics['status']}\n"
f"- Last start time: {orchestrator_metrics['start_time']}\n"
f"- Last end time: {orchestrator_metrics['end_time']}\n"
f"- Number of partitions: {orchestrator_metrics['num_partitions']}\n"
f"- Number of partitions materialized: {orchestrator_metrics['num_materialized']}\n"
f"- Number of failed partitions: {orchestrator_metrics['num_failed']}"
)
# Print the final string
print(output)Getting metrics from the `conversation_classifications` asset.
- Row count: 8127
- Size: 280.32 KB
- Last run id: 0346fbc5-54f5-46a1-8e7a-18299ef93004
- Last run status: SUCCESS
- Last start time: 2024-12-24 07:46:36
- Last end time: 2024-12-24 07:47:09
- Number of partitions: 758
- Number of partitions materialized: 98
- Number of failed partitions: 0Metrics from the `conversation_classifications` asset.
Let’s get a sample of data for those classifications:
from google.cloud import bigquery
import pyarrow.feather as feather
# Construct a BigQuery client object.
client = bigquery.Client()
query = """
select * from `dev_narratives.conversation_classifications`
order by partition_time desc
limit 5"""
# Make an API request.
query_job = client.query(query)
# Wait for the job to complete.
conversation_classifications_df = query_job.result().to_dataframe()
# Write the DataFrame to a Feather file
feather_file = "data/conversation_classifications.feather"
feather.write_feather(conversation_classifications_df, feather_file)
# Pass the file path to the global namespace
globals()['conversation_classifications_feather'] = feather_fileGetting a data sample from the `conversation_classifications` asset.
library(arrow)
# Read the Feather file
feather_file <- reticulate::py$conversation_classifications_feather
# Read the Feather file
conversation_classifications_df <- read_feather(feather_file)
# Display the table
kable(
conversation_classifications_df,
format = "html", # Ensures better rendering in Quarto
escape = TRUE
)Displaying the data sample from the `conversation_classifications` asset.
| CONVERSATION_ID | CLASSIFICATION | PARTITION_TIME |
|---|---|---|
| 1867074284352393331 | True | 2024-12-12 10:00:00 |
| 1867050503504318545 | False | 2024-12-12 10:00:00 |
| 1867073426214519260 | True | 2024-12-12 10:00:00 |
| 1867075620628300041 | True | 2024-12-12 10:00:00 |
| 1867073189039276360 | True | 2024-12-12 10:00:00 |
Then we summarize the events being discussed in those conversations.
import json
from damn_tool.show import show_asset
result = show_asset('narratives/conversation_event_summary', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract and print the desired attributes
asset_details = data["show"]
orchestrator_details = asset_details["From orchestrator"]
warehouse_details = asset_details["From data warehouse"]
# Combine attributes into a single string
output = (
f"- Description: {orchestrator_details['description']}\n"
f"- Compute kind: {orchestrator_details['computeKind']}\n"
f"- Is partitioned: {orchestrator_details['isPartitioned']}\n"
f"- Table type: {warehouse_details['table_type']}\n"
f"- Table schema: {warehouse_details['table_schema']}\n"
f"- Created: {warehouse_details['created']}"
)
# Print the final string
print(output)Getting attributes from the `conversation_event_summary` asset.
- Description: Summary of the event discussed in a conversation
- Compute kind: LangChain
- Is partitioned: True
- Table type: BASE TABLE
- Table schema: narratives
- Created: 2024-12-12T18:45:46.163000+00:00Attributes from the `conversation_event_summary` asset.
And we have the following metrics for this asset:
import json
from damn_tool.metrics import asset_metrics
result = asset_metrics('narratives/conversation_event_summary', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract relevant metrics
orchestrator_metrics = data["metrics"]["From orchestrator"]
dw_metrics = data["metrics"]["From data warehouse"]
# Combine metrics into a single string
output = (
f"- Row count: {dw_metrics['row_count']}\n"
f"- Size: {dw_metrics['bytes']}\n"
f"- Last run id: {orchestrator_metrics['run_id']}\n"
f"- Last run status: {orchestrator_metrics['status']}\n"
f"- Last start time: {orchestrator_metrics['start_time']}\n"
f"- Last end time: {orchestrator_metrics['end_time']}\n"
f"- Number of partitions: {orchestrator_metrics['num_partitions']}\n"
f"- Number of partitions materialized: {orchestrator_metrics['num_materialized']}\n"
f"- Number of failed partitions: {orchestrator_metrics['num_failed']}"
)
# Print the final string
print(output)Getting metrics from the `conversation_event_summary` asset.
- Row count: 289
- Size: 348.86 KB
- Last run id: 0346fbc5-54f5-46a1-8e7a-18299ef93004
- Last run status: SUCCESS
- Last start time: 2024-12-24 07:46:37
- Last end time: 2024-12-24 07:47:59
- Number of partitions: 758
- Number of partitions materialized: 48
- Number of failed partitions: 0Metrics from the `conversation_event_summary` asset.
And a sample of data:
from google.cloud import bigquery
import pyarrow.feather as feather
# Construct a BigQuery client object.
client = bigquery.Client()
query = """
select * except (research_cycles)
from `dev_narratives.conversation_event_summary`
order by partition_time desc
limit 5"""
# Make an API request.
query_job = client.query(query)
# Wait for the job to complete.
conversation_event_summaries_df = query_job.result().to_dataframe()
# Write the DataFrame to a Feather file
feather_file = "data/conversation_event_summaries.feather"
feather.write_feather(conversation_event_summaries_df, feather_file)
# Pass the file path to the global namespace
globals()['conversation_event_summaries_feather'] = feather_fileGetting a data sample from the `conversation_event_summary` asset.
library(arrow)
library(dplyr)
# Read the Feather file
feather_file <- reticulate::py$conversation_event_summaries_feather
# Read the Feather file
conversation_event_summaries_df <- read_feather(feather_file)
conversation_event_summaries_df <- conversation_event_summaries_df %>%
mutate(
EVENT_SUMMARY = substr(EVENT_SUMMARY, 1, 50)
)
# Display the table
kable(
conversation_event_summaries_df,
format = "html", # Ensures better rendering in Quarto
escape = TRUE
)Displaying the data sample from the `conversation_event_summary` asset.
| CONVERSATION_ID | EVENT_SUMMARY | PARTITION_TIME |
|---|---|---|
| 1867041079163306152 | On December 11, 2024, the Supreme Court issued a p | 2024-12-12 07:00:00 |
| 1867022812025602097 | A recent analysis highlights the significant benef | 2024-12-12 07:00:00 |
| 1865150335284662433 | In response to escalating geopolitical tensions, p | 2024-12-07 04:00:00 |
| 1865181471918420443 | In response to escalating threats from Russia and | 2024-12-07 04:00:00 |
| 1865124092875067832 | In response to escalating geopolitical tensions, p | 2024-12-07 01:00:00 |
Finally, we associate each post to a discourse type and extract a narrative from it. Some attributes:
import json
from damn_tool.show import show_asset
result = show_asset('narratives/post_narrative_associations', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract and print the desired attributes
asset_details = data["show"]
orchestrator_details = asset_details["From orchestrator"]
warehouse_details = asset_details["From data warehouse"]
# Combine attributes into a single string
output = (
f"- Description: {orchestrator_details['description']}\n"
f"- Compute kind: {orchestrator_details['computeKind']}\n"
f"- Is partitioned: {orchestrator_details['isPartitioned']}\n"
f"- Table type: {warehouse_details['table_type']}\n"
f"- Table schema: {warehouse_details['table_schema']}\n"
f"- Created: {warehouse_details['created']}"
)
# Print the final string
print(output)Getting attributes from the `post_narrative_associations` asset.
- Description: Associations between social network posts and narrative types
- Compute kind: LangChain
- Is partitioned: True
- Table type: BASE TABLE
- Table schema: narratives
- Created: 2024-12-12T18:46:06.324000+00:00Attributes from the `post_narrative_associations` asset.
And some metrics:
import json
from damn_tool.metrics import asset_metrics
result = asset_metrics('narratives/post_narrative_associations', orchestrator='dagster', data_warehouse='bigquery', configs_dir="../.damn/")
data = json.loads(result)
# Extract relevant metrics
orchestrator_metrics = data["metrics"]["From orchestrator"]
dw_metrics = data["metrics"]["From data warehouse"]
# Combine metrics into a single string
output = (
f"- Row count: {dw_metrics['row_count']}\n"
f"- Size: {dw_metrics['bytes']}\n"
f"- Last run id: {orchestrator_metrics['run_id']}\n"
f"- Last run status: {orchestrator_metrics['status']}\n"
f"- Last start time: {orchestrator_metrics['start_time']}\n"
f"- Last end time: {orchestrator_metrics['end_time']}\n"
f"- Number of partitions: {orchestrator_metrics['num_partitions']}\n"
f"- Number of partitions materialized: {orchestrator_metrics['num_materialized']}\n"
f"- Number of failed partitions: {orchestrator_metrics['num_failed']}"
)
# Print the final string
print(output)Getting metrics from the `post_narrative_associations` asset.
- Row count: 688
- Size: 366.30 KB
- Last run id: 0346fbc5-54f5-46a1-8e7a-18299ef93004
- Last run status: SUCCESS
- Last start time: 2024-12-24 07:48:11
- Last end time: 2024-12-24 07:49:58
- Number of partitions: 758
- Number of partitions materialized: 65
- Number of failed partitions: 0Metrics from the `post_narrative_associations` asset.
Let’s get a sample of that data:
from google.cloud import bigquery
import pyarrow.feather as feather
# Construct a BigQuery client object.
client = bigquery.Client()
query = """
select * from `dev_narratives.post_narrative_associations`
where discourse_type != "N/A"
order by partition_time desc
limit 5"""
# Make an API request.
query_job = client.query(query)
# Wait for the job to complete.
post_narrative_associations_df = query_job.result().to_dataframe()
# Write the DataFrame to a Feather file
feather_file = "data/post_narrative_associations.feather"
feather.write_feather(post_narrative_associations_df, feather_file)
# Pass the file path to the global namespace
globals()['post_narrative_associations_feather'] = feather_fileGetting a data sample from the `post_narrative_associations` asset.
library(arrow)
# Read the Feather file
feather_file <- reticulate::py$post_narrative_associations_feather
# Read the Feather file
post_narrative_associations_df <- read_feather(feather_file)
# Display the table
kable(
post_narrative_associations_df,
format = "html", # Ensures better rendering in Quarto
escape = TRUE
)Displaying the data sample from the `post_narrative_associations` asset.
| POST_ID | DISCOURSE_TYPE | NARRATIVE | PARTITION_TIME |
|---|---|---|---|
| 1867041083688906784 | Critical | This post discusses a significant legal ruling that reflects the ongoing struggle between environmental regulation and economic interests, particularly related to coal usage. The Supreme Court's decision to reject the Kentucky electric utility's request to block the EPA's efforts illustrates the critical dimension of climate change discourse, where economic and political power structures are challenged in favor of public health and environmental protection. It emphasizes the need for robust regulatory frameworks to manage hazardous materials like coal ash, which are direct byproducts of fossil fuel consumption, and highlights the societal implications of maintaining such harmful practices. | 2024-12-12 07:00:00 |
| 1867022813896323229 | Integrative | The post highlights the health and economic benefits of adopting heat pumps, framing climate change as an issue that intertwines environmental and social dimensions. By presenting data on reduced premature deaths, hospital visits, and asthma attacks, the discourse suggests that improving energy efficiency and transitioning to cleaner technologies not only addresses climate change but also significantly enhances public health and economic wellbeing. This integrative perspective encourages a holistic view of climate solutions, emphasizing the need to change societal norms and practices towards sustainable energy use. | 2024-12-12 07:00:00 |
| 1854325713236611518 | Critical | The post questions whether China adheres to the climate agenda, which reflects a critical discourse. It implies skepticism about China's commitment to international climate agreements, possibly due to perceived economic and political interests that may not align with aggressive climate action. This aligns with the broader narrative that addressing climate change requires challenging existing economic systems and power structures, as these can lead to uneven and unsustainable patterns of development and energy use. The post's context, following the election of Donald Trump, who has expressed intentions to roll back climate regulations, further underscores the tension between political actions and global climate commitments. | 2024-11-07 04:00:00 |
| 1854377519069151413 | Critical | This post highlights the social and economic implications of climate change, criticizing the lack of action to mitigate its effects despite the clear evidence of its future costs. The mention of 'our kids & grandkids' underscores the intergenerational impact of climate inaction. The tone suggests frustration with the current economic and political systems that prioritize short-term gains over long-term sustainability, which aligns with the Critical discourse. This reflects a challenge to power structures that maintain high fossil fuel consumption and neglect the urgency of climate policies. | 2024-11-07 04:00:00 |
| 1854336568451797187 | Critical | The post reflects a critical discourse on climate change in the context of Donald Trump's election as President. It implies dissatisfaction and frustration with the electoral outcome, suggesting that the country's leadership is not conducive to addressing climate change. This aligns with the critical discourse type, where climate change is seen as a social problem exacerbated by political structures and leadership decisions that prioritize economic gains from fossil fuels over sustainable development. The post echoes concerns that Trump's policies, which include dismantling climate regulations and promoting fossil fuel production, are at odds with the urgent need for climate action. | 2024-11-07 04:00:00 |
Analytics Assets
Finally, the platform produces a dimensional representation of those assets for reporting purposes. I won’t go into details here, but here’s an overview of the dbt project that generates those assets:
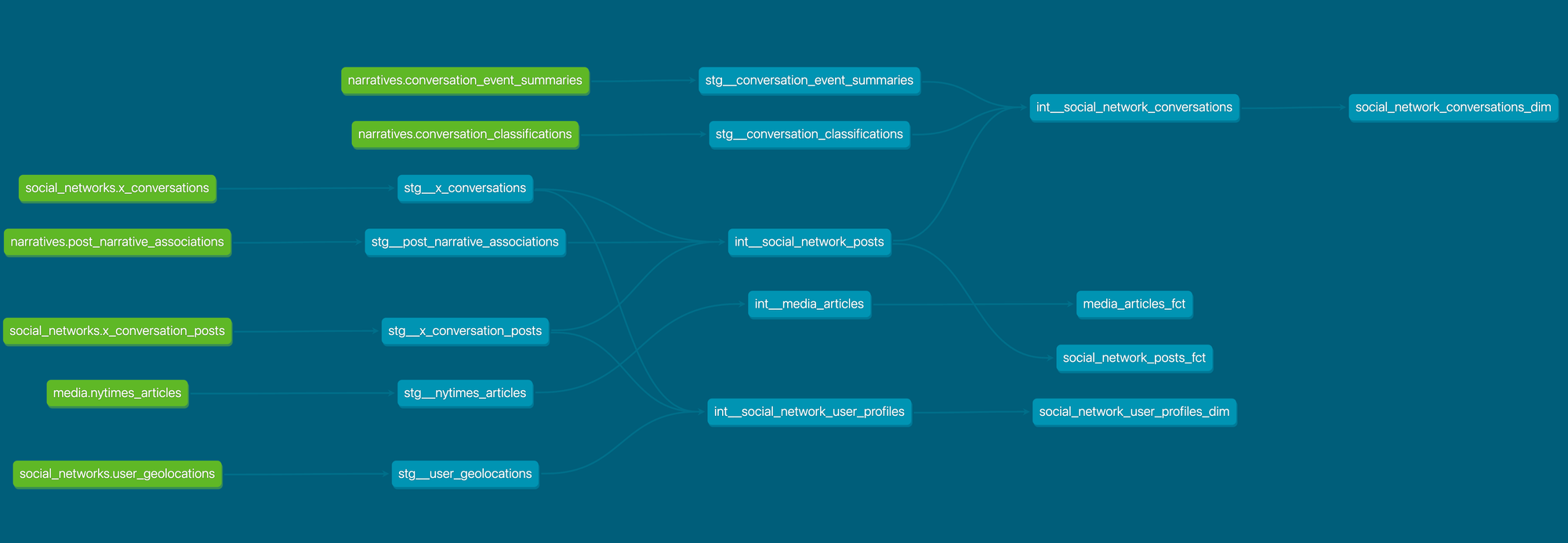
📈 Conclusion
No sexy graphics, no groundbreaking insights. But isn’t that 90% of the work for data product builders? Designing the product, putting the pieces together, setting guardrails, and ensuring data quality.
There’s so much left to improve, but we at least now have a foundation to build upon. And most importantly, some data to explore new corners of our society. Because that’s the ultimate goal of RepublicOfData.io - to explore the dark corners of our society with data. And to get better at the craft of data product building along the way.