How AI Agents Assemble the Climate Narratives Report
This post explores how the assembler agent transforms raw data into the Climate Narratives Report, showcasing AI’s role in streamlining workflows and generating actionable insights.
 Olivier Dupuis
—
—
13 min read min read
Olivier Dupuis
—
—
13 min read min read
I recently published a new edition of the Climate Narratives Report, marking a significant shift in how it’s assembled. AI agents now handle most of the assembly process, with my role limited to verifying output, ensuring factuality, and improving cohesiveness. Over time, I aim to further refine these agents to enhance the quality of the reports and uncover deeper insights into how public opinion on climate change evolves globally.
In this post, I’ll examine the AI-driven assembly process in greater detail, focusing on the agent that brings everything together. For a more visual overview, you can also watch the video tour.
🐝 Swarm Design
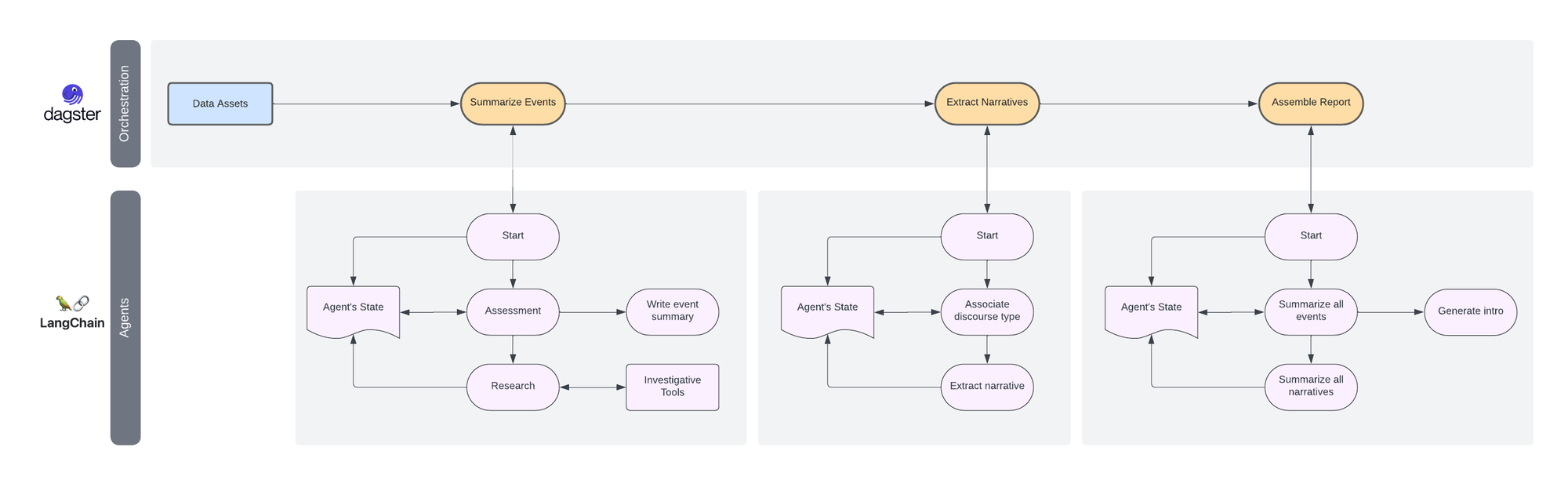
Let's first take a high-level view of the platform and where that agent fits in.
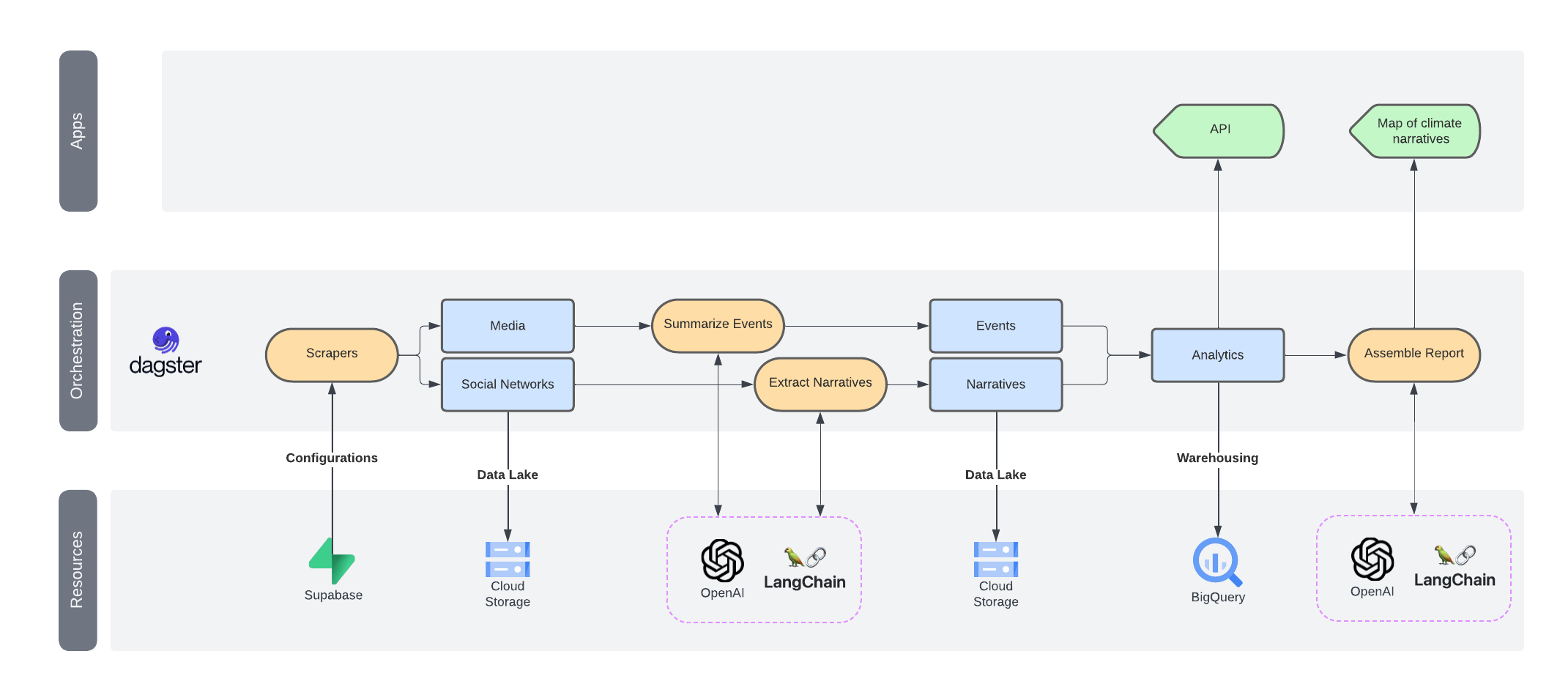
As you can see, multiple agents are involved in the transformation process. Here's a diagram of that swarm:
We've already covered (and presented) the agents that summarize the events and the ones that extract narratives from conversations. This post will dive into the agent that helps assemble weekly reports.
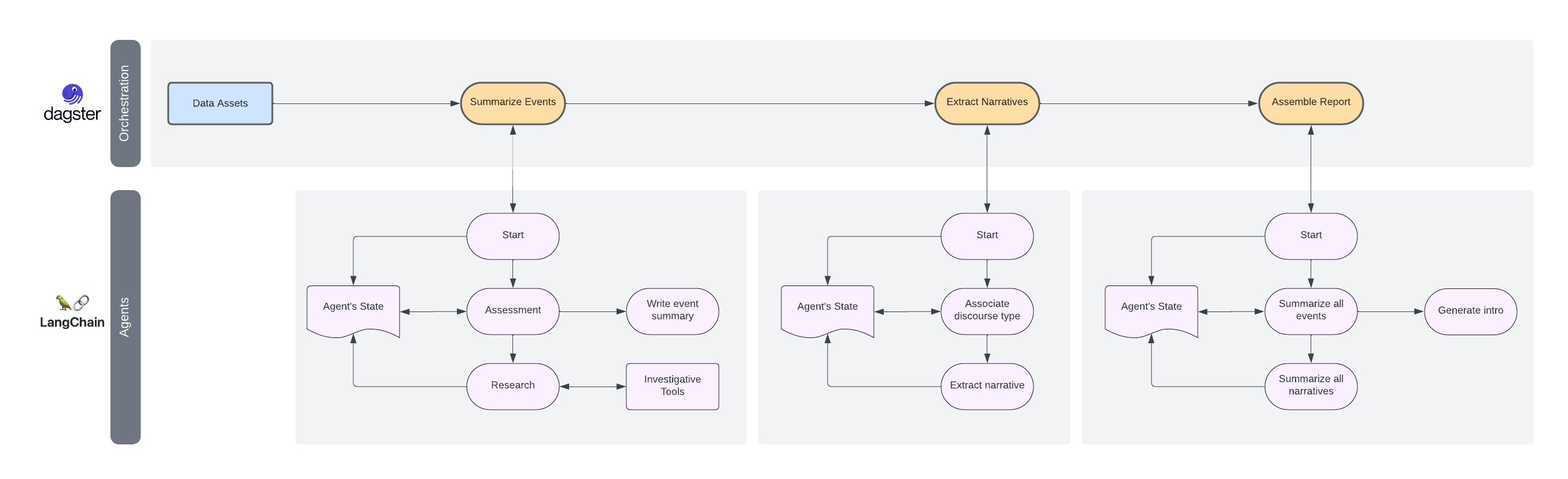
Assembler Agent
Below is a diagram of all the agent's nodes, interdependencies, and execution sequence. We are building our assembler in Hex.
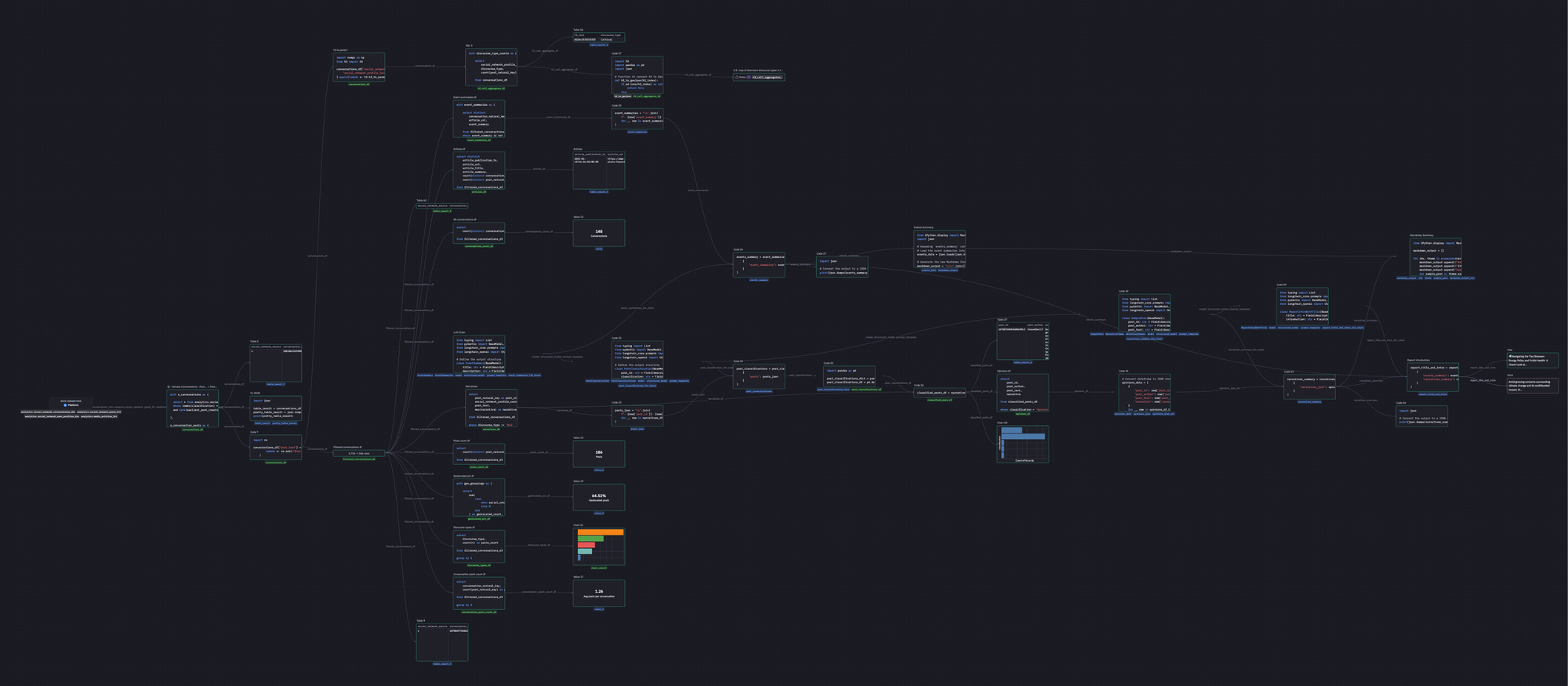
The assembler has seven core functions:
- Gather the data which will be used throughout the report.
- Calculate KPIs of the platform's performance over the week.
- Generate a summary of the climate events that were covered during the week.
- Classify the posts as either being opinions, informative, questions or other.
- Generate a summary of the public perceptions of the week's climate events.
- Draw up a map of the dominant narrative types by region in the U.S.
- Generate an introduction and title for the report.
I will use this week's report as an example of assembly using this agent.
Gather data
I first pull a flattened dataset of all articles, conversations, and enrichments from the past 90 days.
with s_conversations as (
select * from analytics.social_network_conversations_dim
where lower(classification) = 'true'
and date(earliest_post_creation_ts) >= date_add(current_date(), interval -90 day)
),
s_conversation_posts as (
select * from analytics.social_network_posts_fct
),
s_users as (
select * from analytics.social_network_user_profiles_dim
),
s_articles as (
select * from analytics.media_articles_fct
),
final as (
select
s_conversations.social_network_source,
s_conversations.conversation_natural_key,
s_conversations.classification,
s_conversations.event_summary,
s_conversations.earliest_post_creation_ts,
s_conversation_posts.post_natural_key,
s_conversation_posts.post_url,
s_conversation_posts.post_text,
s_conversation_posts.discourse_type,
s_conversation_posts.narrative,
s_conversation_posts.post_creation_ts,
s_users.social_network_profile_natural_key,
s_users.social_network_profile_username,
s_users.social_network_profile_description,
s_users.social_network_profile_location_name,
s_users.social_network_profile_location_country_name,
s_users.social_network_profile_location_country_code,
s_users.social_network_profile_location_admin1_name,
s_users.social_network_profile_location_admin1_code,
s_users.social_network_profile_location_latitude,
s_users.social_network_profile_location_longitude,
s_users.social_network_profile_location_h3_r3,
s_users.social_network_profile_creation_ts,
s_articles.media_source,
s_articles.article_url,
s_articles.article_title,
s_articles.article_summary,
s_articles.article_tags,
s_articles.article_author,
s_articles.article_medias,
s_articles.article_publication_ts
from s_conversations
left join s_conversation_posts on s_conversations.social_network_conversation_pk = s_conversation_posts.social_network_conversation_fk
left join s_users on s_conversation_posts.social_network_user_profile_fk = s_users.social_network_user_profile_pk
left join s_articles on s_conversations.media_article_fk = s_articles.media_article_pk
)
select * from final
order by article_publication_ts, article_url, post_creation_ts
Here's the JSON representation of a sample record:
{
"social_network_source": "x",
"conversation_natural_key": "1881410422571733068",
"classification": "True",
"event_summary": "In January 2025, several major U.S. financial institutions, including the Federal Reserve, announced their withdrawal from climate change advocacy groups amid escalating political and legal pressures, coinciding with the anticipated return of Donald Trump to the presidency. This decision marks a significant shift in the financial sector's engagement with climate initiatives, raising concerns about the implications for sustainable finance and the overall commitment to global climate goals, such as those outlined in the Paris Agreement. The exit of these banks signals a potential reduction in support for funding sustainable projects, which are crucial for addressing climate change and promoting a low-carbon economy.\n\nThe research indicates that the withdrawal may adversely affect ongoing climate initiatives and policies, potentially undermining the progress made towards achieving regulatory and market objectives. The broader context reveals that the ESG movement, which has grown to encompass over $30 trillion in assets, faces scrutiny over data quality and accusations of greenwashing, complicating the narrative around responsible investing. Additionally, the implications of these banks' decisions extend to the leadership role they play in shaping industry standards and practices related to climate action, which could hinder the effectiveness of future climate policies and initiatives.",
"earliest_post_creation_ts": 1737398174000,
"post_natural_key": "1881412370368745907",
"post_url": "https://twitter.com/shicks_sam/status/1881412370368745907",
"post_text": "@miracledan59 Biden forgot to pardon the climate scamers.",
"discourse_type": "Dismissive",
"narrative": "The post reflects a dismissive attitude towards climate change efforts, suggesting that the contributors to climate change, referred to here as 'climate scamers,' are not being held accountable. This aligns with the broader context of skepticism and criticism surrounding climate initiatives, especially given the recent shifts in financial institutions away from supporting climate advocacy. The language used indicates a belief that the urgency and seriousness of climate change are being undermined, especially in light of the anticipated political changes that may deprioritize climate action.",
"post_creation_ts": 1737398638000,
"social_network_profile_natural_key": "2922360215",
"social_network_profile_username": "shicks_sam",
"social_network_profile_description": "Nuclear Power Plant Design Support Engineer \n\nTherfore be ye ready: for in such an hour as ye think not the Son of man cometh.\n\nMathew 24:44",
"social_network_profile_location_name": "South Carolina",
"social_network_profile_location_country_name": "United States",
"social_network_profile_location_country_code": "US",
"social_network_profile_location_admin1_name": "North Carolina",
"social_network_profile_location_admin1_code": "NC",
"social_network_profile_location_latitude": 35.7721,
"social_network_profile_location_longitude": -78.63861,
"social_network_profile_location_h3_r3": "832ad6fffffffff",
"social_network_profile_creation_ts": 1418612997000,
"media_source": "nytimes",
"article_url": "https://www.nytimes.com/2025/01/20/business/trump-climate-action-banks.html",
"article_title": "Big Banks Quit Climate Change Groups Ahead of Trump\u2019s Term",
"article_summary": "Several large U.S. financial institutions, including the Federal Reserve, have withdrawn from the networks after years of growing political and legal pressure.",
"article_tags": "global warming,banking and financial institutions,corporate social responsibility,blackrock inc,federal reserve system,jpmorgan chase & company,goldman sachs group inc",
"article_author": "Eshe Nelson",
"article_medias": "https://static01.nyt.com/images/2025/01/20/multimedia/20banks-climate-lbwq/20banks-climate-lbwq-mediumSquareAt3X.jpg",
"article_publication_ts": 1737360011000
}
KPIs
From this raw data, we first want to aggregate a few KPIs to give us a feel of the platform's performance over the weekend.

Summary of Climate Events
Now, we're starting to get into the generative responsibilities of the agent. For all of the 148 conversations above, we will go through all the associated event summaries and extract the main events discussed throughout the week.
This is the structure of the output we want:
from typing import List
from pydantic import BaseModel, Field
# Define the output structure
class EventSummary(BaseModel):
title: str = Field(description="The title of the event, starting with a representative emoji.")
description: str = Field(description="A brief description of the event.")
article_urls: List[str] = Field(
description="A list of up to 3 article URLs associated with the event."
)
class EventSummaries(BaseModel):
top_events: List[EventSummary] = Field(
description="A list of the top 5 events discussed in the past 7 days."
)
And this is the LLM chain we've put together using LangChain's libraries:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Define the model and output configuration
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(EventSummaries)
# Define the prompt
prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert in summarizing public discourse on climate-related topics. Your task is to identify the top 5 events discussed in the past 7 days from a list of event summaries and provide concise, structured output.
For each event, include:
1. A **title** summarizing the event.
2. A **description** explaining the event in a few sentences.
3. A list of up to 3 **article URLs** associated with the event.
Your response should be well-structured, informative, and useful for stakeholders to quickly understand the most important events.
"""
),
(
"human",
"""Please generate a summary of the top 5 events from the following data:
Event Summaries:
{event_summaries}
Structure your response as follows:
- top_events: A list of up to 5 events, each containing:
- title: A concise title for the event.
- description: A short explanation of the event.
- article_urls: Up to 3 URLs associated with the event.
"""
),
]
)
# Define the processing chain
event_summaries_llm_chain = prompt_template | structured_model
We then get event summaries such as the following one:
#### **🔌 Chris Wright Nominated as Energy Secretary**
Chris Wright, founder of a fracking services company, was nominated for the U.S. Energy Secretary position. His support for both fossil fuels and renewable energy has sparked debate over the future direction of U.S. energy policy and the balance between economic interests and environmental sustainability.
Articles:
- [https://www.nytimes.com/2025/01/15/climate/chris-wright-energy-secretary-nominee.html](https://www.nytimes.com/2025/01/15/climate/chris-wright-energy-secretary-nominee.html)
Classification of Posts
One refinement I've been experimenting with is classifying the types of posts within a conversation. Some posts are questions, others informative, while others might offer opinions.
Considering that we want to summarize public perceptions, my experiment is whether we would get clearer threads in those perceptions by only keeping opinions.
Let's again start with the structured output I want to generate:
from typing import List
from pydantic import BaseModel, Field
# Define the output structure
class PostClassification(BaseModel):
post_id: str = Field(description="The unique identifier for the post.")
classification: str = Field(description="The category of the post, e.g., Opinion, Informative, Question, or Other.")
rationale: str = Field(description="The reasoning behind the classification.")
class PostClassifications(BaseModel):
classified_posts: List[PostClassification] = Field(
description="A list of posts with their respective classifications and rationales."
)
And the LLM chain being used:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Define the model and output configuration
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(PostClassifications)
# Define the prompt
prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert in analyzing public discourse. Your task is to classify social media posts into categories based on their content.
The possible categories are:
- **Opinion:** Posts where the user expresses a personal viewpoint.
- **Informative:** Posts providing factual information or sharing news.
- **Question:** Posts where the user is asking a question.
- **Other:** Posts that do not fit the above categories.
For each post, provide:
1. The post_id.
2. A classification (one of Opinion, Informative, Question, Other).
3. A brief rationale explaining why the post fits the chosen category.
Be concise and ensure the classifications are accurate.
"""
),
(
"human",
"""Please classify the following posts:
Posts:
{posts}
Structure your response as follows:
- classified_posts: A list of classifications, where each item includes:
- post_id: The unique ID of the post.
- classification: The category of the post.
- rationale: A brief explanation of the classification.
"""
),
]
)
# Define the processing chain
post_classification_llm_chain = prompt_template | structured_model
I can then append those classifications to my main dataframe and visualize the distribution:
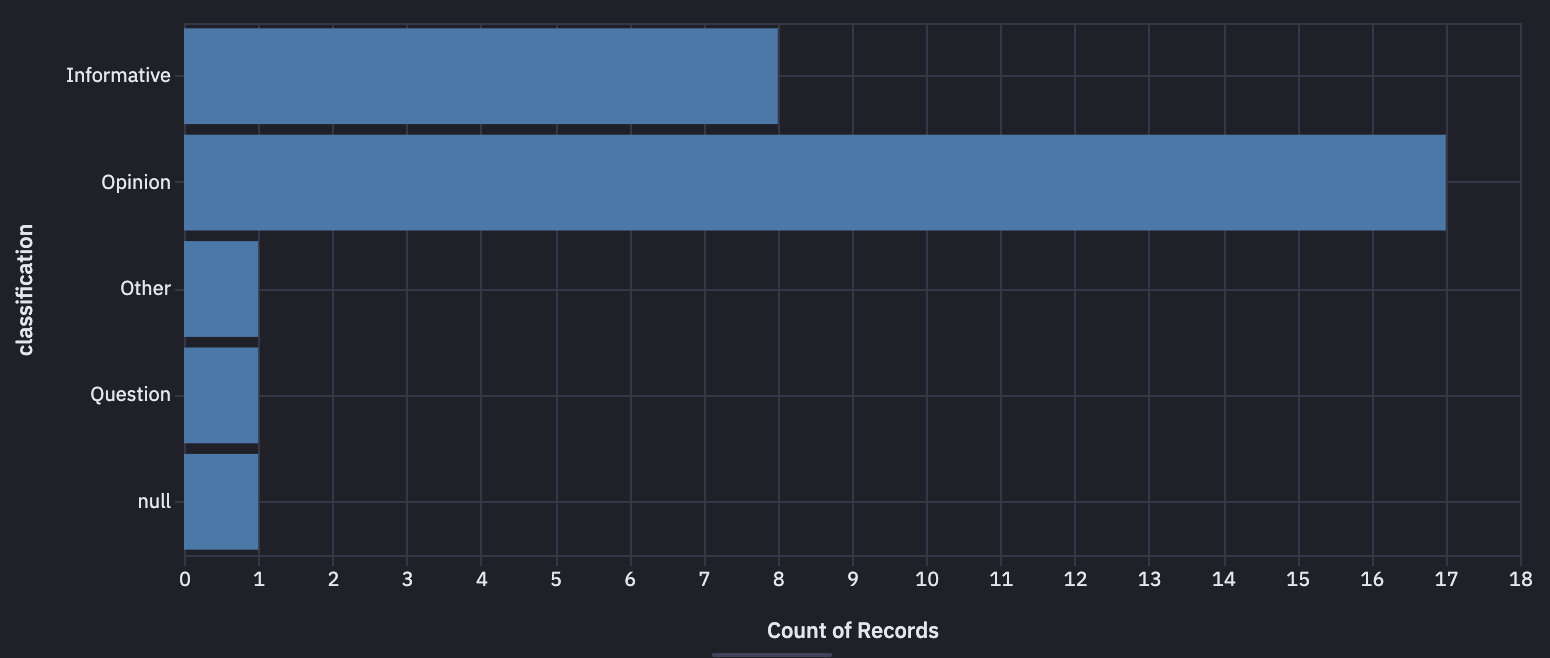
Summary of Public Perceptions
Now that I have those opinions, I can summarize the public perceptions for the week.
Same process. Let's start with the structured output:
from typing import List
from pydantic import BaseModel, Field
class SamplePost(BaseModel):
post_id: str = Field(description="The unique identifier of the sample post")
post_author: str = Field(description="The author of the sample post")
post_text: str = Field(description="The text associated to this post")
narrative: str = Field(description="The narrative associated to this post")
class NarrativeTheme(BaseModel):
name: str = Field(description="A descriptive name for a grouped themed of narratives, starting with a representative emoji.")
description: str = Field(description="A description of the theme that is grouping those narratives together")
sample_posts: List[SamplePost] = Field(description="A list of sampled posts that are representative of that narrative theme")
class NarrativeThemes(BaseModel):
narrative_themes: List[NarrativeTheme] = Field(description="A list of themes which groups narratives together.")
The LLM chain definition:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(NarrativeThemes)
prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are a discourse expert tasked with extracting key themes in the narratives picked up from conversations about climate events. Your output will help stakeholders understand the public opinions about key climate events from the past 14 days.
Your task involves:
1. Identifying **key themes** from narratives taken from climate event conversations. Avoid generic or high-level categorizations such as "biophysical", "critical," "dismissive," or "integrative." Instead, focus on specific ideas or recurring topics within the conversations.
2. Grouping similar narratives under these themes, providing a descriptive and unique name for each group.
3. Writing concise descriptions for each theme that clearly communicate the underlying idea or trend without referring to broad classifications.
4. For each theme, select a few representative posts.
Your response must provide unique and actionable insights into recent climate discourses, helping stakeholders understand specific public opinions and concerns.
"""
),
(
"human",
"""Please generate a stakeholder brief from the following narratives collected over the past 7 days:
Narratives (in a JSON structure):
{narratives_json}""",
),
]
)
# Task
narratives_summary_llm_chain = prompt_template | structured_model
Which outputs themes such as this one:
### 🔍 Skepticism About Leadership
Doubt is expressed regarding the qualifications and motivations of political appointees in environmental roles, with a focus on how political agendas could adversely impact climate regulations.
Sample Posts:
- https://x.com/Cindybinmo/status/1879935189708882388: "That’s isn’t a bad thing, Zeldin is long on common sense."
- https://x.com/Tankerboom10/status/1879942998471164111: "Environmental experiences got us nothing but wildfires and taxes."
Geography of Dominating Discourses
An essential focus of this data platform is tracking the geographical dimension of climate discourses. However, to do that, we need high-quality geolocation of the users contributing to the discussions. This task is complex, and I've been gradually tuning the process.
It's important because I want to track how discourses shift within each geographical area. For example, it would be great to see how certain discourses are introduced into an area, how they morph over time, and so on.
We're far from that kind of analysis, but our first step is to determine the dominant discourse types in each area.
To do this, we are using the H3 global grid system. Within our pipeline, we have a process to translate lat/long coordinates to an H3 cell. I'm using a high resolution so that I can aggregate those cells into high-level areas afterwards if I want to.
And this is what I'm doing here as a first step. I want to group up my H3 cells to a lower resolution.
import numpy as np
from h3 import h3
conversations_df["social_network_profile_location_h3_r2"] = conversations_df[
"social_network_profile_location_h3_r3"
].apply(lambda x: h3.h3_to_parent(str(x), 2) if pd.notnull(x) else np.nan)
I can then identify the most common discourse types per H3 cell:
with discourse_type_counts as (
select
social_network_profile_location_h3_r2,
discourse_type,
count(post_natural_key) as discourse_type_count,
from conversations_df
where discourse_type != 'N/A'
and social_network_profile_location_country_code = 'US'
group by 1, 2
),
discourse_type_ranking as (
select
social_network_profile_location_h3_r2,
discourse_type,
discourse_type_count,
ROW_NUMBER() OVER (PARTITION BY social_network_profile_location_h3_r2 ORDER BY discourse_type_count DESC) AS discourse_type_rank
from discourse_type_counts
)
select
social_network_profile_location_h3_r2 as h3_cell,
discourse_type
from discourse_type_ranking
where discourse_type_rank = 1
And map this out in our notebook:
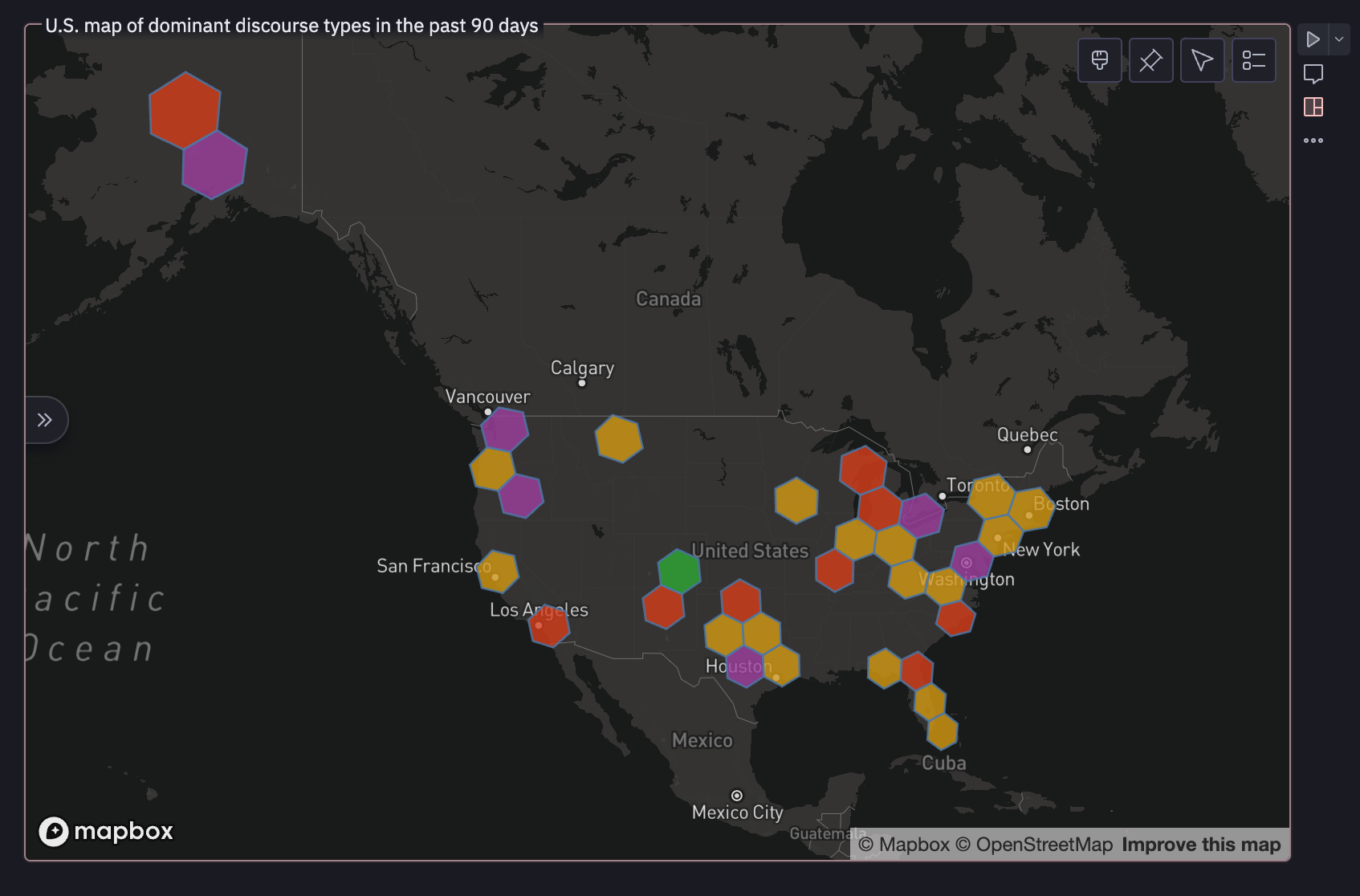
Generate Intro and Title
Finally, I want to generate a title and introduction that will capture the spirit of this week's report. We'll use another agent for that.
Let's start with the expected structured output:
from typing import List
from pydantic import BaseModel, Field
class ReportIntroWithTitle(BaseModel):
title: str = Field(description="A highly specific and focused title for the Weekly Climate Narratives Review report, emphasizing a key theme or event")
introduction: str = Field(description="A concise introduction focused on a single key aspect of the report, providing context and setting the stage for the analysis")
Once again, we build an LLM chain which follows that same pattern:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(ReportIntroWithTitle)
prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are a skilled editor and communicator tasked with drafting a highly specific title and a focused introduction for the Weekly Climate Narratives Review report.
The report analyzes online conversations about climate change, and your role is to:
1. Select **one specific aspect** of the report to highlight in the title and introduction.
2. Generate a **title** that is concise, descriptive, and directly tied to the chosen focus.
3. Craft an **introduction** that elaborates on the specific focus, offering context and setting the stage for deeper analysis in the report.
Guidelines:
- The title should clearly reflect the focus, such as a major event, theme, or policy decision discussed in the report.
- The introduction should be no longer than 200 words, zooming in on the chosen theme while maintaining relevance to the overall report.
- Both should spark curiosity and interest, aligning with the report’s goal of fostering understanding and empathy around climate issues.
"""
),
(
"human",
"""Please craft a title and introduction for this week's report based on the following summaries:
Events Summary:
{events_summary}
Narratives Summary:
{narratives_summary}
"""
),
]
)
# Task
report_title_and_intro_llm_chain = prompt_template | structured_model
Giving us an output such as this:
# 🌍 Navigating the Ties Between Energy Policy and Public Health: A Closer Look at the EPA's PFAS Warning
Amid growing concerns surrounding climate change and its multifaceted impact, this week’s report emphasizes the alarming warning issued by the EPA regarding elevated levels of PFAS in sewage sludge used as fertilizer. This revelation not only raises significant health risks but also calls into question the practices of agricultural industries and the accountability of regulatory bodies.
As discussions amplify about the detrimental effects of contaminated fertilizers, this incident serves as a critical juncture for both environmental and public health discourse. The relationship between energy policy and agricultural practices highlights systemic vulnerabilities in our regulatory framework and the broader implications of fossil fuel dependency. Understanding these interconnected challenges is essential as we strive for sustainable solutions in our agriculture and energy sectors.
In the following sections, we will delve deeper into the narratives emerging from this issue, exploring public sentiment and the urgency of recognizing the health risks tied to our current practices.
Next Steps
Improve Geographical Insights
Understanding the geographical dynamics of climate discourse is a key priority for the platform’s evolution. While the current approach leverages the H3 grid system to analyze discourse patterns at a granular level, there’s room to refine both data accuracy and interpretability. The challenge lies in aligning location data with meaningful narratives while avoiding noise caused by incomplete or ambiguous user data.
Upcoming iterations will focus on:
- Enriching geolocation data by incorporating more robust metadata from user profiles and cross-referencing with external datasets.
- Experimenting with different H3 resolutions to balance granularity and readability, enabling clearer regional trends.
- Adding tools to visualize how narratives flow geographically, offering stakeholders insights into how climate sentiments propagate or evolve across regions.
These improvements will enable us to answer questions like: Where are the most dismissive or critical climate narratives emerging? How do narratives shift as they move from one region to another?
Gather More Conversations from Other Social Networks
Expanding the range of data sources is critical to painting a more comprehensive picture of climate discourse. Currently, much of the data is drawn from platforms like X (formerly Twitter), which skews toward real-time, public conversations.
The goal is to broaden this lens by:
- Integrating new platforms such as Reddit, YouTube comments, and LinkedIn discussions, which offer diverse perspectives from long-form debates, professional communities, and niche groups.
- Developing custom ingestion pipelines for less traditional platforms, ensuring data quality while adapting to each platform’s API limitations or content structure.
- Investigating how narratives differ across platforms. For example, are climate narratives on Reddit more community-driven and explanatory, while LinkedIn focuses on policy or industry-specific themes?
Bringing in these additional sources will provide a richer dataset, reduce platform bias, and create opportunities to uncover unique insights that might otherwise remain hidden.