Optimizing and Engineering LLM Prompts with LangChain and LangSmith
 Olivier Dupuis
—
—
9 min read min read
Olivier Dupuis
—
—
9 min read min read
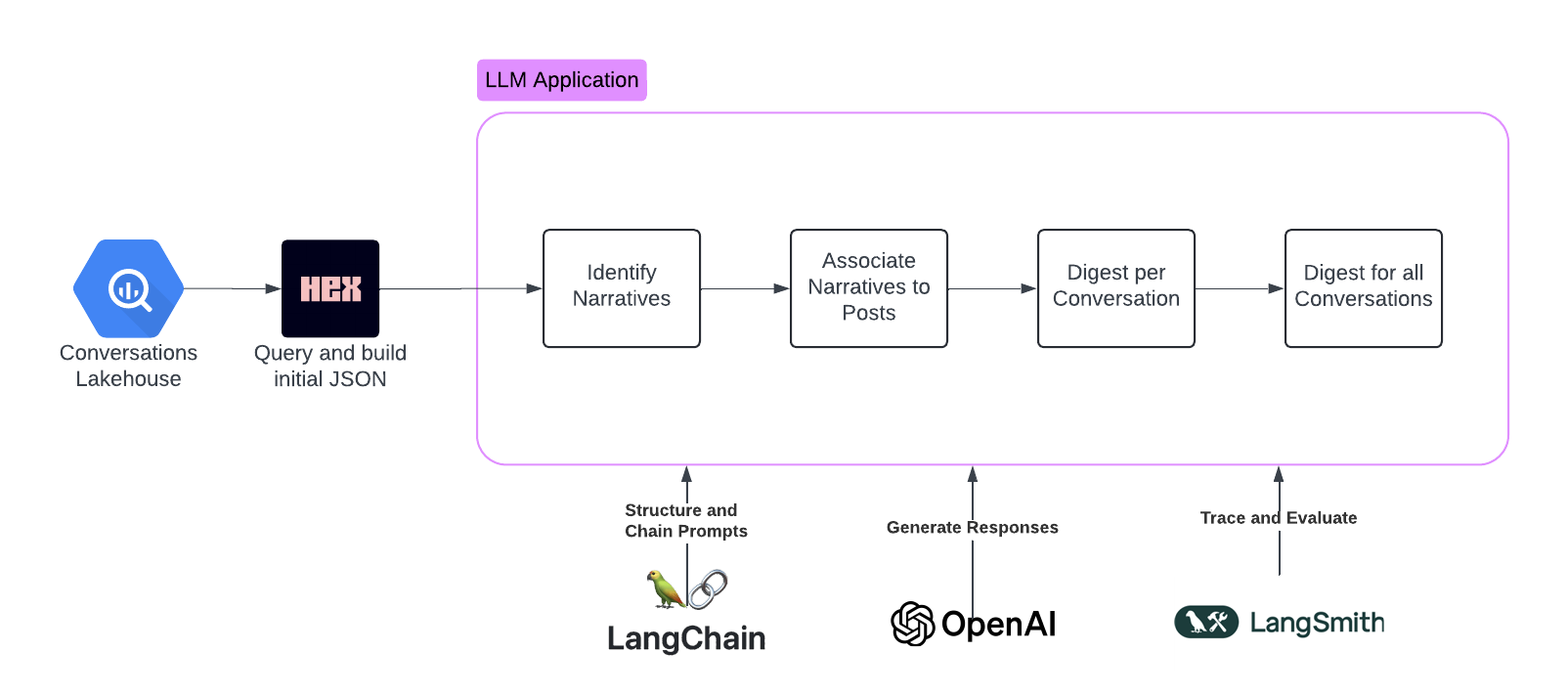
Conversations Analyzer - Part 2 of 3
- Part 1: Building up a Local Generative AI Engine with Ollama, Fabric and OpenWebUI
- Part 2: Optimizing and Engineering LLM Prompts with LangChain and LangSmith
- Part 3: Enforcing Structure and Assembling Our AI Agent
In my previous post, I discussed the importance of prompting to achieve good results from large language models (LLMs). I expressed skepticism about the term “prompt engineering,” arguing that it felt more like an art than a science due to the unpredictable nature of LLM behaviour. However, this perspective received some pushback.
One counterargument suggested that while we may encounter “prompt drift,” we can still engineer highly performant prompts. We can enhance accuracy and reduce drift by categorizing problems into smaller tasks for agents and benchmarking prompts against different models.
This made me reconsider my stance on “engineering” in the context of prompts. Unlike mathematical functions where y = f(x) is predictable and testable, prompting doesn’t guarantee precise outcomes. Nevertheless, the comparison to social sciences is enlightening. Social phenomena can’t always be quantified mathematically, yet they can still be studied scientifically. Similarly, prompt engineering can benefit from systematic methods to optimize and refine prompts.
In this article, we’ll explore how to optimize prompts, piece them together using LangChain, and monitor and evaluate them using LangSmith.
From Art to Engineering: Frameworks, Techniques, and Tools
Prompt engineering has often been viewed as more of an art due to its unpredictable nature. However, we can take a more systematic and engineering-oriented approach with the right frameworks, techniques, and tools. This section delves into the various methods available for prompt engineering, ranging from manual frameworks to programmatic approaches, as well as the tools used for monitoring and evaluation.
Manual and Programmatic Frameworks
The release of ChatGPT in early 2023 sparked widespread excitement and creativity in prompt use. People asked ChatGPT to perform various tasks, from composing Beatles-style songs about analytics engineering to generating SQL queries for business questions. This period was marked by a sense of boundless possibility, where prompts were experimented freely and iteratively.
However, as our needs grew more sophisticated and we sought to produce accurate and formatted responses, we confronted the inherent randomness of LLM outputs. This unpredictability highlighted our limited understanding of the internal workings of LLMs, which function by predicting the next token based on largely opaque patterns.
This is where prompt engineering comes into play. It moves beyond ad hoc experimentation to a more structured approach to crafting prompts reliably generating desired responses. We can broadly categorize these approaches into manual and programmatic frameworks:
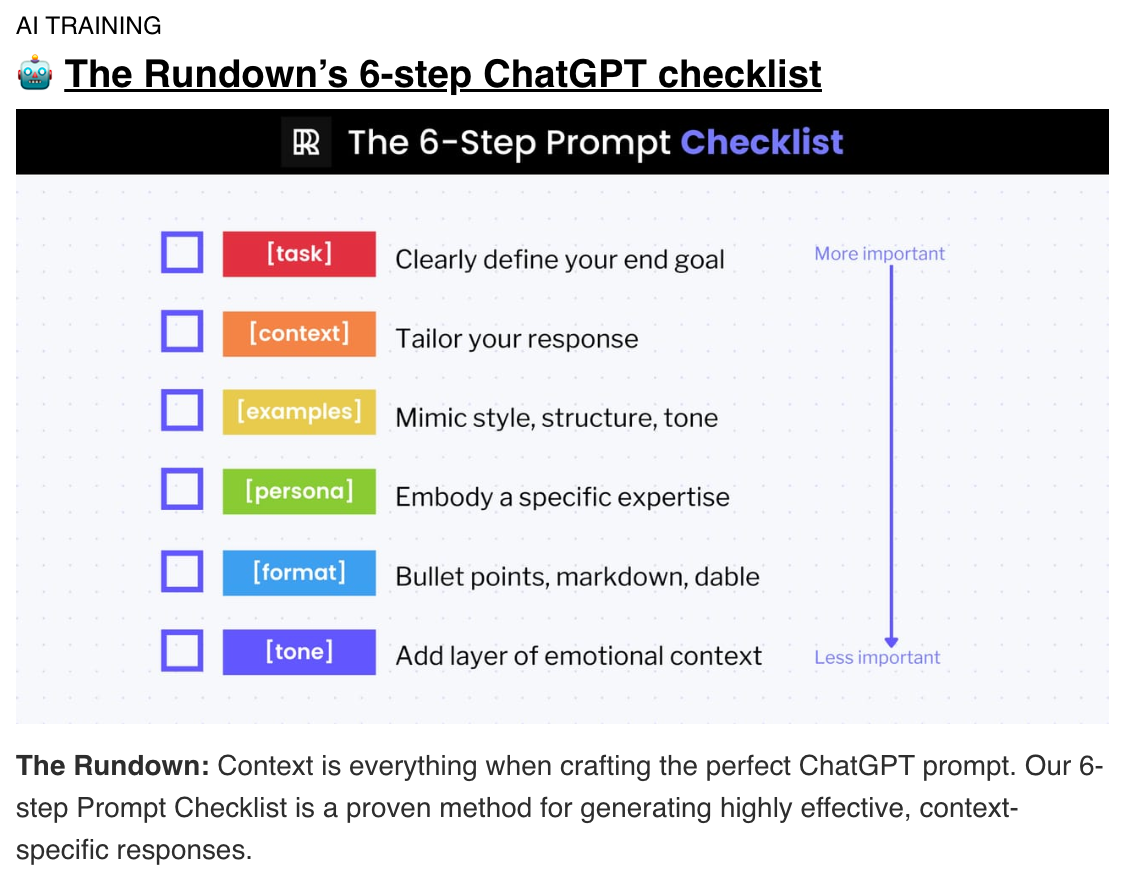
Manual Frameworks: These involve human intuition and creativity to craft prompts. They rely heavily on trial and error, iterative adjustments, and qualitative assessments. Here is an example of a checklist shared in a widely circulating AI newsletter.
Programmatic Frameworks: These leverage automated processes and algorithms to optimize prompts. An example is DSPy, which shifts the focus from tweaking individual prompts to designing robust systems.
From the DSPy documentation:
DSPy does two things. First, it separates the flow of your program (modules) from the parameters (LM prompts and weights) of each step. Second, DSPy introduces newoptimizers, which are LM-driven algorithms that can tune the prompts and/or the weights of your LM calls, given ametricyou want to maximize.
And from an article introducing DSPy:
The idea at the high level is that we will be using an Optimizer to compile our code which makes language model calls so that each module in our pipeline is optimized into a prompt that is automatically generated for us or a new fine-tuned set of weights for our language model that fits the task that we are trying to solve.
That's a mouthful. But the main idea is that instead of manually optimizing your prompts, you codify that tuning process using the programmatic framework.
Tools for Monitoring and Evaluation
As large language models (LLMs) become critical components of our infrastructure, monitoring and evaluating their usage, output, and performance is imperative. Treating LLMs as essential resources means implementing robust logging and analysis mechanisms to ensure they function efficiently and reliably. This involves tracking how LLMs are utilized, evaluating the quality of their outputs, and continuously optimizing their performance.
The available tools for monitoring and evaluation can be broadly categorized into several key features:
• 💰 Cost Tracking: Monitoring the expenses associated with LLM usage to manage and optimize costs effectively.
• 📊 Performance Metrics: Analyzing response times, accuracy, and consistency to ensure high-quality outputs.
• 🔍 Output Analysis: Evaluating the quality and relevance of the generated responses.
• 🔄 Continuous Optimization: Iteratively refining prompts based on performance data and feedback.
By understanding and leveraging these tools, we can shift from an ad hoc approach to a more systematic and engineering-oriented process for prompt design. This transition allows us to treat prompt engineering as an art and a rigorous discipline akin to other engineering practices.
While the initial phase of prompt engineering involved much trial and error, we now have the frameworks and tools to approach it with the precision and reliability of traditional engineering disciplines. We can systematically refine our LLM applications by integrating cost tracking, performance metrics, output analysis, and continuous optimization.
This brings us to the practical application of these principles. In the following sections, we will explore using LangChain and LangSmith to apply an engineering process to our Generative AI application, optimizing and chaining tasks to build a robust and efficient system.
Redesigning the Conversations Analyzer for Optimal Performance
Building on our understanding of frameworks and tools, this section focuses on optimizing a specific application: the Conversations Analyzer. We’ll start by re-evaluating our initial prototype design, discussing previously used tools and approaches, and then outlining a new approach for improved performance and accuracy.
Our initial prototype leveraged tools such as Ollama, Fabric, and OpenWebUI. While these tools provided a good starting point, we encountered several challenges in achieving consistent and accurate outputs. The need for a more systematic approach became evident as we sought to enhance the reliability and precision of the Conversations Analyzer.
With the insights gained from exploring frameworks and tools for prompt engineering, we are now ready to redesign our prototype. We aim to incorporate more robust methodologies and leverage advanced tools to optimize performance. This redesign addresses the previous prototype's limitations and fully exploits the LangChain ecosystem's potential.
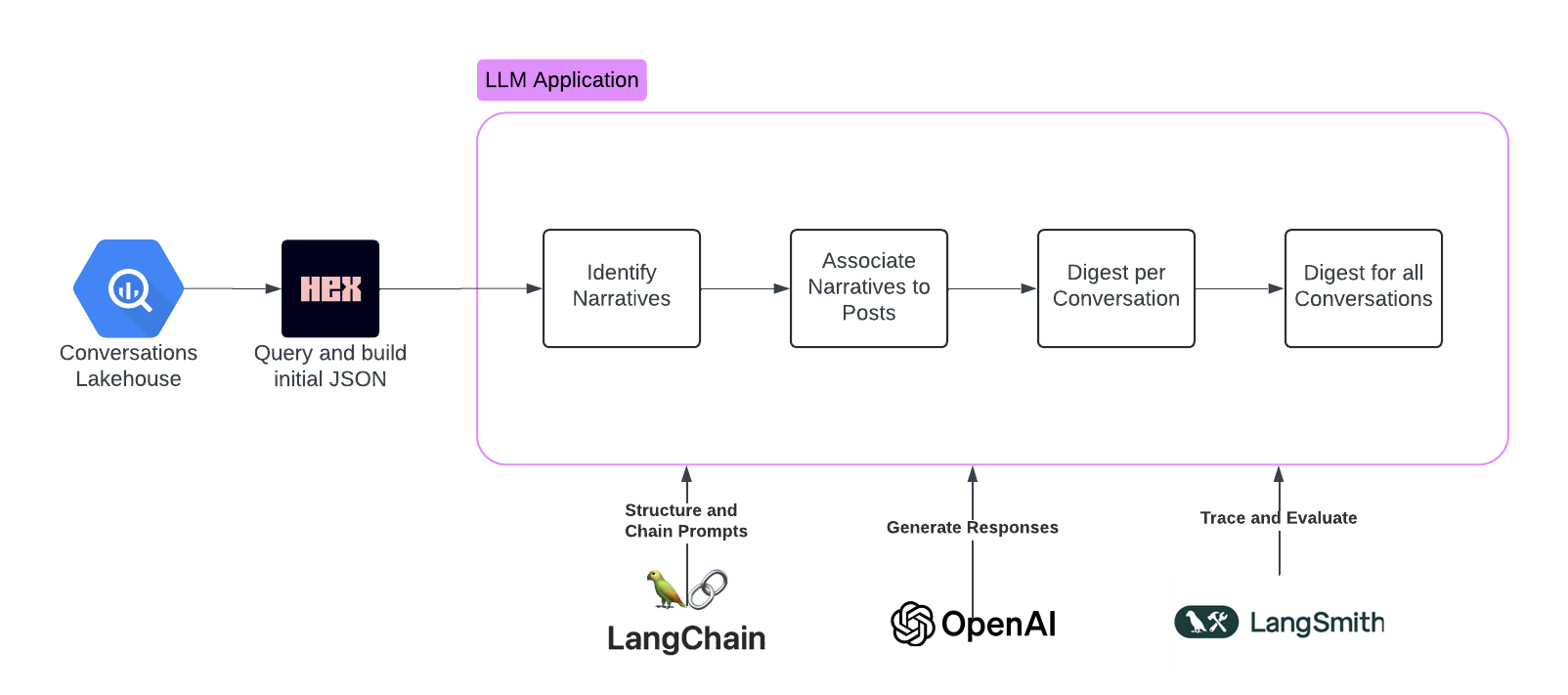
Query our Lakehouse and Build a Conversation JSON Object
Before we dive in, let's make sure to get the latest LangChain packages installed and ready to go.
!pip install langchain==0.2.5
!pip install langchain-core==0.2.9
!pip install langsmith==0.1.81
!pip install langchain-openai==0.1.9
We'll now import a sample of conversations from the RepublicOfData.io platform.
import pandas as pd
conversations_df = pd.read_csv("social_signals.csv")
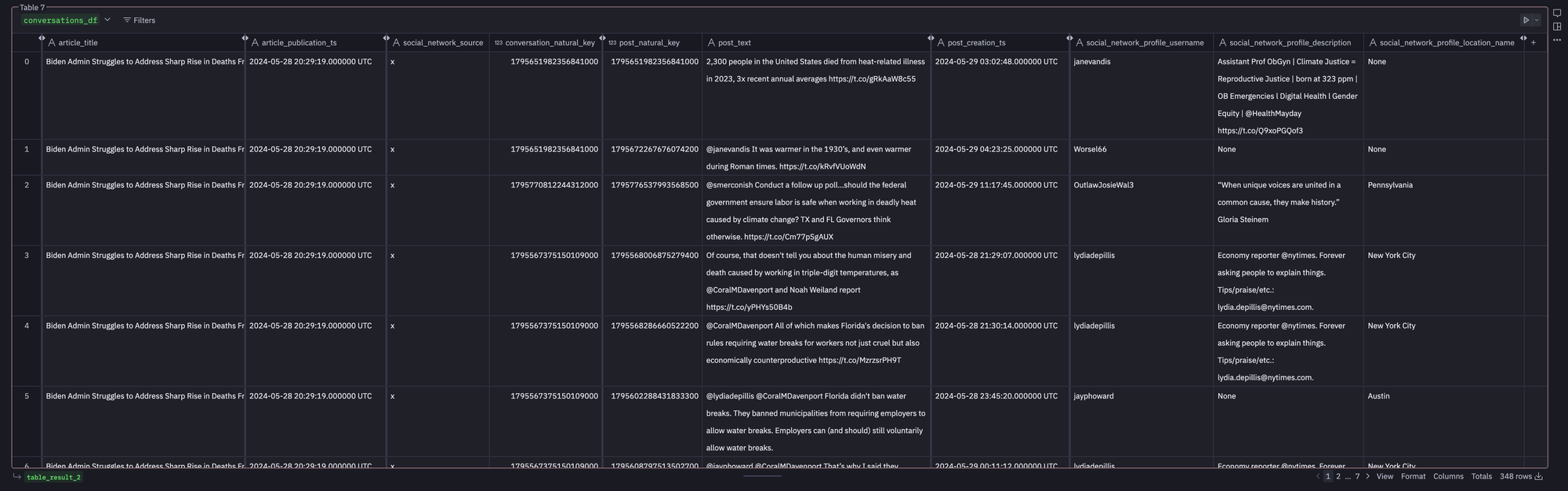
Below is a preview of several rows and columns from the dataset.
Let's now identify the most active conversations.
select
conversation_natural_key,
count(distinct post_natural_key) as post_count
from conversations_df
group by 1
order by 2 desc
limit 10
Finally, let's create a JSON object that organizes our conversations.
conversations_filtered_df = conversations_df[
(conversations_df["conversation_natural_key"] == 1795461303563112576)
].sort_values(by="post_creation_ts")[
["conversation_natural_key", "post_natural_key", "post_creation_ts", "post_text"]
]
# Group by conversation_natural_key and aggregate post_texts into a list ordered by post_creation_ts
conversation_filtered_list = (
conversations_filtered_df.groupby("conversation_natural_key")
.apply(lambda x: x.sort_values("post_creation_ts")[["post_natural_key", "post_creation_ts", "post_text"]].to_dict(orient='records'))
.reset_index(name="posts")
)
# Convert the DataFrame to JSON
conversation_filtered_json = conversation_filtered_list.to_json(orient="records")
After we generate the output, we receive the following result:
[
{
"conversation_natural_key": 1795461303563112576,
"posts": [
{
"post_natural_key": 1795461303563112576,
"post_creation_ts": "2024-05-28 14:25:07.000000 UTC",
"post_text": "Over the past year of record-shattering warmth, the average person on Earth experienced 26 more days of abnormally high temperatures than they otherwise would have, were it not for human-induced climate change, scientists said Tuesday. https://t.co/RVI2ieLHYp"
},
{
"post_natural_key": 1795461844116672893,
"post_creation_ts": "2024-05-28 14:27:16.000000 UTC",
"post_text": "@nytimes Lol the same \u201cscientist\u201d who said the COVID death jab vaccine was \u201csafe and effective\u201d and would prevent transmission. LOLOLOL"
},
...
]
}
]
Defining a GenAI Task
Let's form a prompt for our Generative AI task. This task will be in charge of analyzing all posts within a conversation to recognize the narratives conveyed in that conversation.
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# Components
model = ChatOpenAI(model="gpt-4")
parser = StrOutputParser()
# Prompt
system_template = """
# IDENTITY and PURPOSE
You are an expert at extracting narratives from conversations.
# STEPS
1. Ingest the json file which has conversations on climate change
2. Take your time to process all its entries
3. Parse all conversations and extract all narratives
4. Each narrative should have a label and a short description (5 to 10 words)
# OUTPUT INSTRUCTIONS
Generate a JSON object that only includes the list of narratives with the label and short description as fields.
"""
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
# Task
chain = prompt_template | model | parser
Let's test it with the conversation we sampled earlier.
narratives_json = chain.invoke({"text": conversation_filtered_json})
Behold the results we've obtained:
import json
narratives_dict = json.loads(narratives_json)
narratives_formatted_json = json.dumps(narratives_dict, indent=4)
# Display formatted JSON in markdown cell
print(f"```json\n{narratives_formatted_json}\n```")
[
{
"label": "Human-induced climate change",
"description": "Impact of human activities on global warming"
},
{
"label": "Climate change skepticism",
"description": "Distrust and denial of climate change data"
},
{
"label": "Climate change solutions",
"description": "Potential ideas to tackle climate change"
},
{
"label": "Climate change and weather",
"description": "Exploring connection between climate change and weather patterns"
},
{
"label": "Climate change and global politics",
"description": "Interplay of climate change and geopolitical issues"
}
]
Constructing Evaluation Datasets and Metrics
The above result is satisfactory, but if I were to consider using a different language model, such as GPT-3.5, to reduce my expenses, how could I assess the quality of its output? This is where LangSmith comes into play.
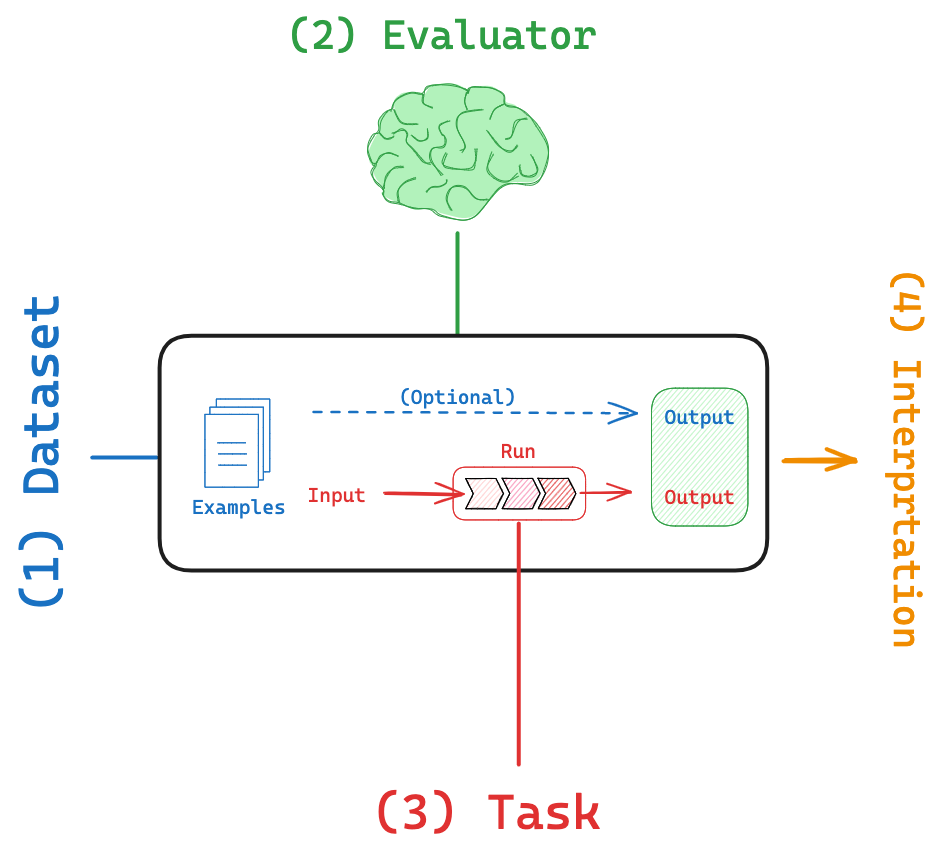
The first thing we need to do is create a dataset against which we'll evaluate the performance of our Generative AI task.
For example, in the conversation above, let's manually curate its narratives. This will serve as the ground truth for our evaluations.
[
{
"conversation_natural_key": 1795461303563112576,
"narratives": [
{
"label": "Climate Change Attribution",
"description": "Discussion on human-induced climate change"
},
{
"label": "Climate Change Denial",
"description": "Claims that climate change is a hoax"
},
{
"label": "Climate Change Solutions",
"description": "Suggestions to tackle climate change challenges"
}
]
}
]
Let's go ahead and create that dataset in LangSmith.
from langsmith import Client
client = Client()
# Define dataset
dataset_name = "Conversations Analyzer - Identify Narratives"
dataset = client.create_dataset(dataset_name)
client.create_examples(
inputs=[
{"question": """
```json
[
{
"conversation_natural_key": 1795461303563112576,
"posts": [
{
"post_natural_key": 1795461303563112576,
"post_creation_ts": "2024-05-28 14:25:07.000000 UTC",
"post_text": "Over the past year of record-shattering warmth, the average person on Earth experienced 26 more days of abnormally high temperatures than they otherwise would have, were it not for human-induced climate change, scientists said Tuesday. https://t.co/RVI2ieLHYp"
},
{
"post_natural_key": 1795461844116672893,
"post_creation_ts": "2024-05-28 14:27:16.000000 UTC",
"post_text": "@nytimes Lol the same \u201cscientist\u201d who said the COVID death jab vaccine was \u201csafe and effective\u201d and would prevent transmission. LOLOLOL"
},
...
]
}
]
```
"""},
],
outputs=[
{"answer": """
[
{
"conversation_natural_key": 1795461303563112576,
"narratives": [
{
"label": "Climate Change Attribution",
"description": "Discussion on human-induced climate change"
},
{
"label": "Climate Change Denial",
"description": "Claims that climate change is a hoax"
},
{
"label": "Climate Change Solutions",
"description": "Suggestions to tackle climate change challenges"
}
]
}
]
"""},
],
dataset_id=dataset.id,
)
Finally, let's define a metric to evaluate a prompt's performance against the above dataset. We'll use the LLM-as-a-judge evaluator.
from langchain_openai import ChatOpenAI
from langchain_core.prompts.prompt import PromptTemplate
from langsmith.evaluation import LangChainStringEvaluator
_PROMPT_TEMPLATE = """You are an expert professor specialized in grading students' answers to questions.
You are grading the following question:
{query}
Here is the real answer:
{answer}
You are grading the following predicted answer:
{result}
Respond with CORRECT or INCORRECT:
Grade:
"""
PROMPT = PromptTemplate(
input_variables=["query", "answer", "result"], template=_PROMPT_TEMPLATE
)
eval_llm = ChatOpenAI(temperature=0.0)
qa_evaluator = LangChainStringEvaluator("qa", config={"llm": eval_llm, "prompt": PROMPT})
Evaluating our GenAI Task
Now that all the components are in place, we can rerun our chain using the sample conversation and evaluate its output against our test dataset using our evaluation metrics.
Let's run our prompt and evaluate its output against the ground truth.
# from langsmith.evaluation import evaluate
experiment_results = evaluate(
langsmith_app, # Your AI system
data=dataset_name, # The data to predict and grade over
evaluators=[qa_evaluator], # The evaluators to score the results
experiment_prefix="openai-gpt-4", # A prefix for your experiment names to easily identify them
)
If we head to LangSmith, we see that our dataset now has an experiment against it.
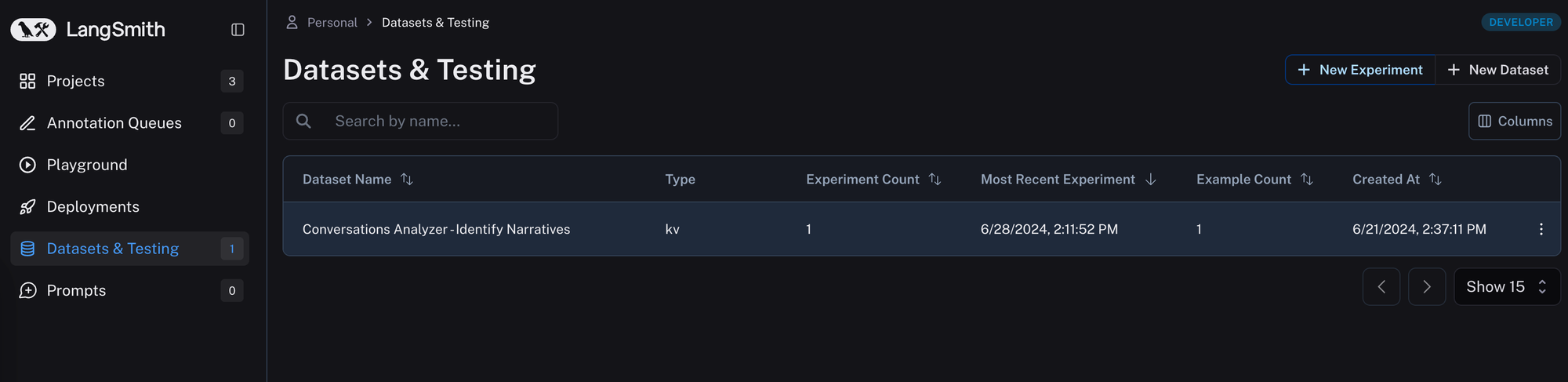
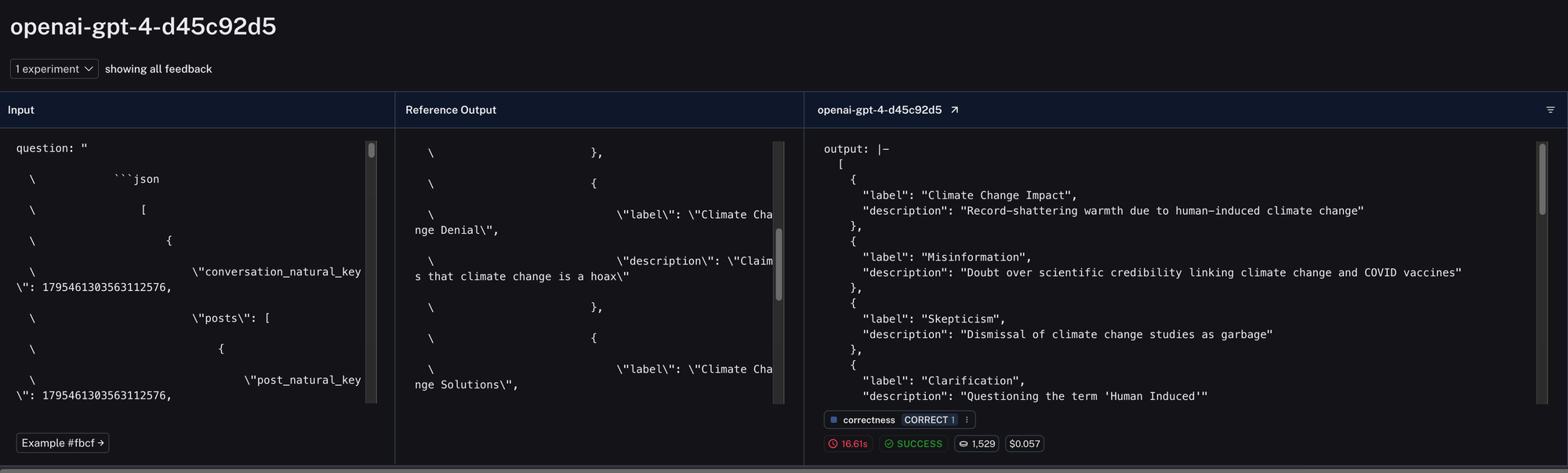
When examining the experiment, we observe the input prompt, the ground truth (reference output), and the actual result obtained. We also have several important metrics related to the output:
- The duration of the execution
- The execution status
- The number of tokens utilized
- The cost
Additionally, our evaluator confirmed that the answer was "correct" in comparison to our ground truth during the "correctness" assessment.
Conclusion and Next Steps
In this article, we delved into a structured approach to the efficient development of prompts, utilizing a range of frameworks, tools, and techniques. In this series's upcoming and final part, we will finalize our LLM application by integrating all the discussed concepts and tools to create a fully functional and optimized Generative AI system.
Key points for enhancing our evaluation process:
- Develop all tasks systematically
- Integrate the tasks cohesively
- Continuously monitor and enhance the performance of GenAI tasks