The Geography of Climate Discourses
Explore how climate change conversations differ across the U.S. with a map highlighting dominant discourse types in each state. See how regional attitudes shape the discussion on this issue.
 Olivier Dupuis
—
—
10 min read min read
Olivier Dupuis
—
—
10 min read min read
We aim to gather conversations about climate change from various social networks and analyze how people's perceptions and opinions vary based on location.
To achieve this, we will use the following design.
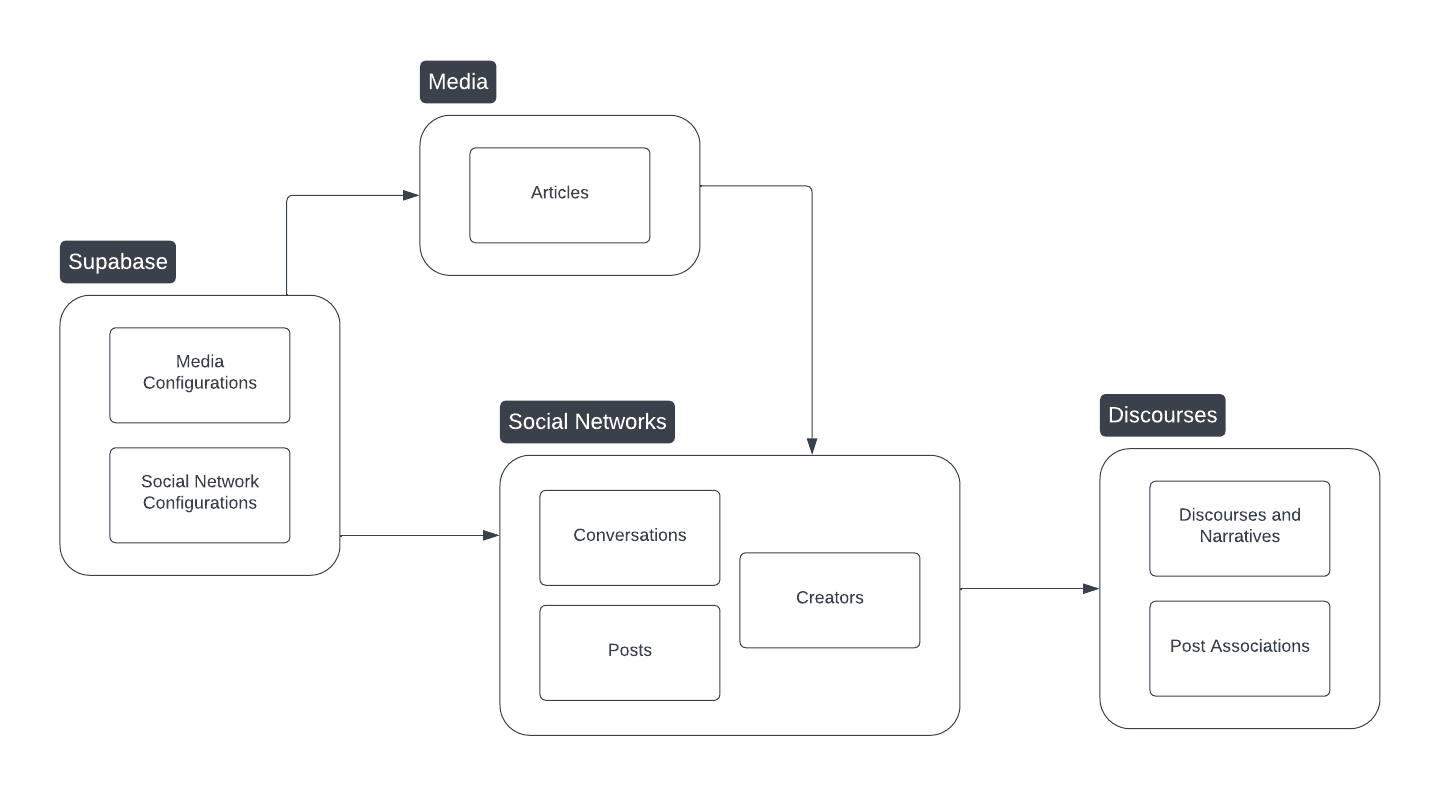
- We have a database with the media feeds and social network configurations to scrape.
- We then have 2 data products responsible for collecting and exposing media articles and social network conversations.
- Finally, we have an AI agent to analyze the conversations and classify them into four discourse types.
This notebook is a prototype of the design, serving as a proof of concept to demonstrate how we can utilize the data we've gathered to analyze climate discussions based on geographical locations. For more information and in-depth exploration, please check out the public repository, which includes all the code and documentation for this project.
Theoretical Framework
Let’s first talk about the theoretical framework we use to classify the discourses.
We will reference the book "Climate and Society" by Robin Leichenko and Karen O’Brien, a seminal work that offers a comprehensive framework for understanding climate discourses.
In this book, the authors propose a framework to understand the different discourses on climate change. They identify four main discourses:
- Biophysical: “Climate change is an environmental problem caused by rising concentrations of greenhouse gases from human activities. Climate change can be addressed through policies, technologies, and behavioural changes that reduce greenhouse gas emissions and support adaptation.”
- Critical: “Climate change is a social problem caused by economic, political, and cultural processes that contribute to uneven and unsustainable patterns of development and energy usage. Addressing climate change requires challenging economic systems and power structures that perpetuate high levels of fossil fuel consumption.”
- Dismissive: “Climate change is not a problem at all or at least not an urgent concern. No action is needed to address climate change, and other issues should be prioritized.”
- Integrative: “Climate change is an environmental and social problem that is rooted in particular beliefs and perceptions of human-environment relationships and humanity’s place in the world. Addressing climate change requires challenging mindsets, norms, rules, institutions, and policies that support unsustainable resource use and practice.”
We will use this framework to classify the discourses we collect from social networks.
Data
In early 2024, we collected conversations from X that discussed climate-related articles from the New York Times.
- The data spans from March 28, 2024, to May 30.
- During that time, we collected 655 articles, 7164 conversations and 7974 posts.
- Those posts came from 6578 users.
- We were able to geolocate 3005 of those users.
- That gives us 2071 posts with geolocation data for the users.
- Of those posts, we have 1380 posts geolocated in the United States.
Let’s load that sample data.
conversations_df <- read.csv("../data/climate_conversations.csv")And have a glimpse of the first few rows.
kable(head(conversations_df, n=5))| post_id | conversation_id | author_id | author_username | author_description | admin1_name | article_url | post_text | post_creation_ts |
|---|---|---|---|---|---|---|---|---|
| 1.775708e+18 | 1.775605e+18 | 2.580420e+07 | azgreg | Just a simple man from the Arizona desert trying to get through another day. | Arizona | https://www.nytimes.com/2024/04/02/climate/global-warming-clouds-solar-geoengineering.html | @cflav Didn’t anybody watch Snowpiercer? | 2024-04-04T02:12:35 |
| 1.778153e+18 | 1.778150e+18 | 9.022995e+17 | PeterjsBeattie | 💙veritas vos liberabit💙 🎖️ News Weather Politics News Politics News Technology Science Entertainment Music Gov Officials & Agencies | Florida | https://www.nytimes.com/2024/04/10/climate/ocean-heat-records.html | @nytimes Climate change? What Climate Change? https://t.co/QdhRy8xyrZ | 2024-04-10T20:08:53 |
| 1.790122e+18 | 1.790122e+18 | 1.967564e+07 | mattroush | Husband, dad, grandpa, recovering journalist now in college PR. Proud member Woke Army, Senior Division. MAGAts blocked for the same reason I clean up messes. | Michigan | https://www.nytimes.com/2024/05/13/climate/electric-grid-overhaul-ferc.html | Oops, I mean one BILLION dollars. Reminds me of a certain movie. | 2024-05-13T20:48:46 |
| 1.776318e+18 | 1.776315e+18 | 2.184802e+07 | LouisPeitzman | Mary Testa once said I was great. Bylines: NY Times, Vulture, Time, BuzzFeed. lpeitzman@gmail.com | New York | https://www.nytimes.com/2024/04/04/climate/trains-planes-carbon-footprint-pollution.html | @Jonnynono NEVER. | 2024-04-05T18:35:12 |
| 1.778114e+18 | 1.778100e+18 | 7.930656e+07 | cranberryhorn | 2 BS; 2 MS degrees. APRN, High School Biology and A&P teacher. Since 2008, RN in ER St Patrick Hospital Missoula, MT 2:46 Marathon 1980 female. ME running HOF | Montana | https://www.nytimes.com/2024/04/10/climate/ocean-heat-records.html | @bkaydw @cardon_brian Thank you so much for sharing this article. I cancelled my NYT due to their continual promotion of DJT and @GOP. I still do want to follow science! | 2024-04-10T17:31:31 |
Climate Conversations
Conversations can sometimes deviate from their original purpose, resulting in not all discussions being about climate change. Therefore, we employed an AI agent to determine which conversations focused on climate change.
Here is the code for the AI agent that classifies the conversations.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langsmith import traceable
class ConversationClassification(BaseModel):
"""Classify if a conversation is about climate change"""
conversation_id: str = Field(description="A conversation's id")
classification: bool = Field(
description="Whether the conversation is about climate change"
)
# Agent to classify conversations as about climate change or not
@traceable
def initiate_conversation_classification_agent():
# Components
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(ConversationClassification)
prompt_template = ChatPromptTemplate.from_messages(
[
(
"human",
"Classify whether this conversation is about climate change or not: {conversation_posts_json}",
),
]
)
# Task
chain = prompt_template | structured_model
return chainThen, here’s the code that uses that agent to classify the conversations.
import json
import pandas as pd
from prototype.conversation_classification_agent import (
initiate_conversation_classification_agent,
)
from prototype.utils import get_conversations
conversations_df = get_conversations()
# Classify conversations as about climate change or not
conversation_classifications_df = pd.DataFrame(
columns=["conversation_id", "classification"]
)
conversation_classification_agent = initiate_conversation_classification_agent()
# Iterate over all conversations and classify them
for _, conversation_df in conversations_df.iterrows():
conversation_dict = conversation_df.to_dict()
conversation_json = json.dumps(conversation_dict)
conversation_classifications_output = conversation_classification_agent.invoke(
{"conversation_posts_json": conversation_json}
)
new_classification = pd.DataFrame([conversation_classifications_output.dict()])
conversation_classifications_df = pd.concat(
[conversation_classifications_df, new_classification], ignore_index=True
)
# Save classified conversations to a new csv file
conversation_classifications_df.to_csv(
"data/conversation_classifications.csv", index=False
)traceable decorator. This feature of the LangChain framework enables us to trace the agent's execution and store the logs for auditing purposes.
Let’s see the results of that classification.
conversation_classifications <- read.csv("../data/conversation_classifications.csv")
conversation_classifications %>%
head(n=5) %>%
kable()| conversation_id | classification |
|---|---|
| 1.532010e+18 | False |
| 1.773510e+18 | False |
| 1.773709e+18 | False |
| 1.773743e+18 | True |
| 1.773825e+18 | False |
Let’s visualize the distribution of conversations that are about climate change.
conversation_classifications %>%
count(classification) %>%
kable()| classification | n |
|---|---|
| False | 173 |
| True | 153 |
We end up with 153 geolocated conversations about climate change. Let’s start associating their posts to discourses and map which discourses dominates per region.
Discourses
We are now using a second agent to classify the conversations into the 4 discourses we talked about earlier.
from typing import List
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langsmith import traceable
# Define classes for LLM task output
class PostAssociation(BaseModel):
"""Association between post and narrative"""
post_id: str = Field(description="A post's id")
text: str = Field(description="A post's text")
discourse: str = Field(description="The associated discourse's label")
class PostAssociations(BaseModel):
"""List of associations between posts and narratives"""
post_associations: List[PostAssociation]
# Agent to classify posts to discourses
@traceable
def initiate_post_association_agent():
# Components
model = ChatOpenAI(model="gpt-4o")
parser = PydanticOutputParser(pydantic_object=PostAssociations)
# Prompt
system_template = """
# IDENTITY and PURPOSE
You are an expert at associating discourse types to social network posts.
# STEPS
1. Ingest the first json object which has all the posts from a social network conversation on climate change.
2. Consider the discourse type definitions provided below.
3. Take your time to process all those entries.
4. Parse all posts and associate the most appropriate discourse type to each individual post.
5. It's important that if no discourse is relevant, the post should be classified as N/A.
5. Each association should have the post's text and the discourse's label.
# DISCOURSE TYPES
1. Biophysical: "Climate change is an environmental problem caused by rising concentrations of greenhouse gases from human activities. Climate change can be addressed through policies, technologies, and behavioural changes that reduce greehouse gas emissions and support adaptation."
2. Critical: "Climate change is a social problem caused by economic, political, and cultureal procsses that contribute to uneven and unsustainable patterns of development and energy usage. Addressing climate change requires challenging economic systems and power structures that perpetuate high levels of fossil fuel consumption."
3. Dismissive: "Climate change is not a problem at all or at least not an urgent concern. No action is needed to address climate change, and other issues should be prioritized."
4. Integrative: "Climate change is an environmental and social problem that is rooted in particular beliefs and perceptions of human-environment relationships and humanity's place in the world. Addressing climate change requires challenging mindsets, norms, rules, institutions, and policies that support unsustainable resource use and practice."
5. N/A: "No discourse is relevant to this post."
# OUTPUT INSTRUCTIONS
{format_instructions}
"""
prompt_template = ChatPromptTemplate.from_messages(
[
("system", system_template),
(
"human",
"Here's a json object which has all the posts from a social network conversation on climate change: {conversation_posts_json}",
),
]
).partial(format_instructions=parser.get_format_instructions())
# Task
chain = prompt_template | model | parser
return chainAnd here’s the code that uses that agent to associate posts to discourses.
import json
import pandas as pd
from prototype.post_association_agent import initiate_post_association_agent
from prototype.utils import get_conversations
conversations_df = get_conversations()
classifications_df = pd.read_csv("data/conversation_classifications.csv")
# Filter conversations classified as about climate change
climate_change_conversations_df = conversations_df[
conversations_df["conversation_id"].isin(
classifications_df[classifications_df["classification"] == True][
"conversation_id"
]
)
]
# # Associate posts with a discourse type
post_associations_df = pd.DataFrame(columns=["post_id", "discourse_type"])
post_association_agent = initiate_post_association_agent()
# Iterate over all conversations and classify them
for _, conversation_df in climate_change_conversations_df.iterrows():
conversation_dict = conversation_df.to_dict()
conversation_json = json.dumps(conversation_dict)
try:
post_associations_output = post_association_agent.invoke(
{"conversation_posts_json": conversation_json}
)
for association in post_associations_output.post_associations:
new_row = {
"post_id": association.post_id,
"discourse_type": association.discourse,
}
post_associations_df = pd.concat(
[post_associations_df, pd.DataFrame([new_row])], ignore_index=True
)
except Exception as e:
print(
f"Failed to associate posts in conversation {conversation_df['conversation_id']}"
)
print(e)
# Save classified conversations to a new csv file
post_associations_df.to_csv("data/post_associations_df.csv", index=False)Let’s see the results of that discourse association.
post_associations <- read.csv("../data/post_associations_df.csv")
post_associations %>%
head(n=5) %>%
kable()| post_id | discourse_type |
|---|---|
| 1.774115e+18 | Biophysical |
| 1.774115e+18 | Critical |
| 1.774110e+18 | Biophysical |
| 1.774151e+18 | Integrative |
| 1.774596e+18 | Biophysical |
And visualize the distribution of discourses.
post_associations %>%
count(discourse_type) %>%
kable()| discourse_type | n |
|---|---|
| Biophysical | 116 |
| Critical | 82 |
| Dismissive | 93 |
| Integrative | 58 |
| N/A | 339 |
Geographical Distribution
Now that we have the cleaned up, relevant conversations and their associated discourses, let’s pull it all together.
full_posts <- conversations_df %>%
inner_join(conversation_classifications, by = "conversation_id") %>%
inner_join(post_associations, by = "post_id") %>%
filter(classification == "True") %>%
filter(tolower(discourse_type) != "n/a") %>%
filter(admin1_name != "")
full_posts %>%
head(n=1) %>%
kable()| post_id | conversation_id | author_id | author_username | author_description | admin1_name | article_url | post_text | post_creation_ts | classification | discourse_type |
|---|---|---|---|---|---|---|---|---|---|---|
| 1.778153e+18 | 1.77815e+18 | 9.022995e+17 | PeterjsBeattie | 💙veritas vos liberabit💙 🎖️ News Weather Politics News Politics News Technology Science Entertainment Music Gov Officials & Agencies | Florida | https://www.nytimes.com/2024/04/10/climate/ocean-heat-records.html | @nytimes Climate change? What Climate Change? https://t.co/QdhRy8xyrZ | 2024-04-10T20:08:53 | True | Dismissive |
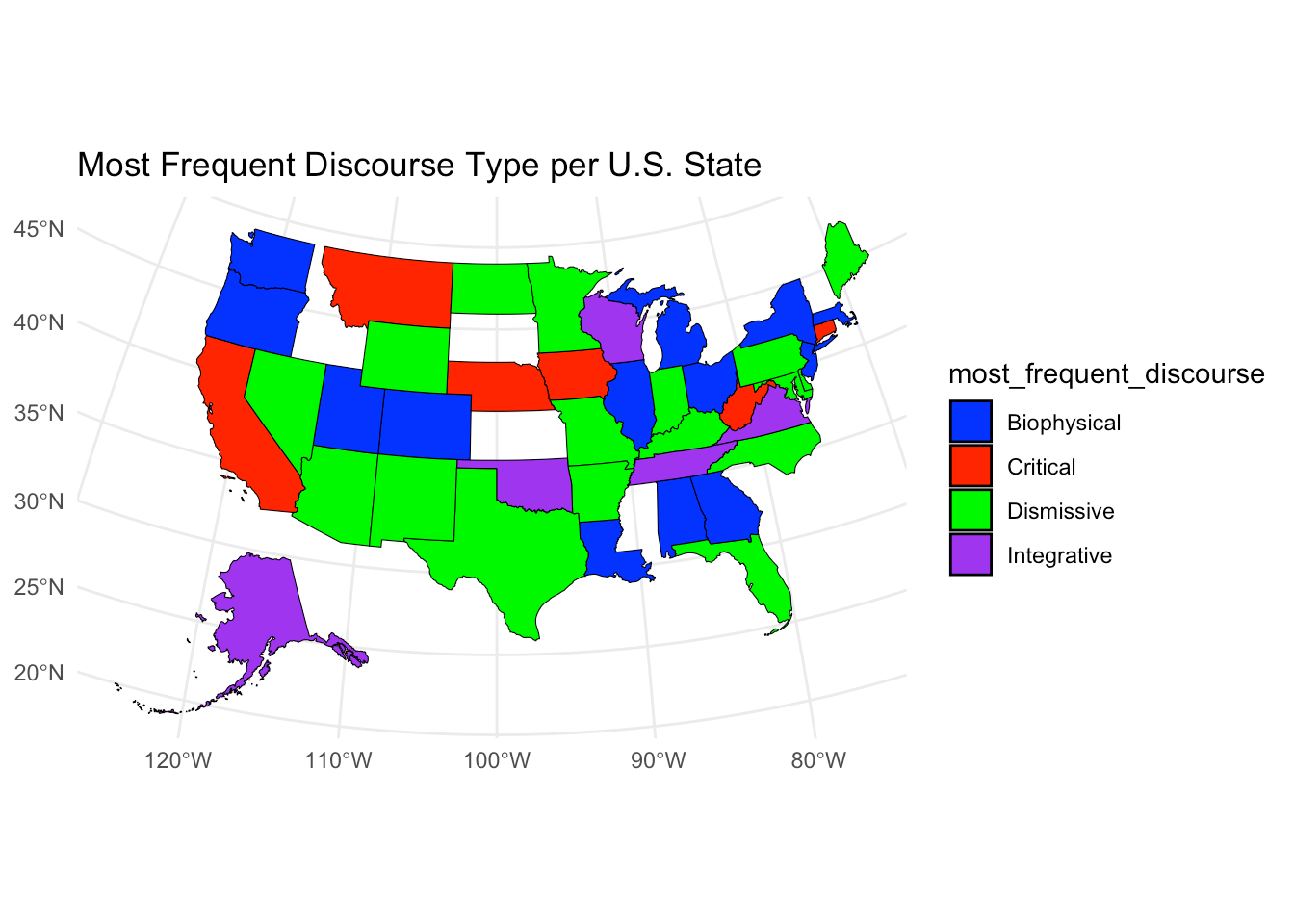
And now let’s see the distribution of discourses by geography, with the most frequent discourse type per state.
discourses_geo_summary <- full_posts %>%
count(discourse_type, admin1_name) %>%
pivot_wider(names_from = discourse_type, values_from = n, values_fill = list(n = 0)) %>%
rowwise() %>%
mutate(most_frequent_discourse = names(.)[which.max(c_across(-admin1_name)) + 1]) %>%
ungroup()
discourses_geo_summary %>%
kable()| admin1_name | Biophysical | Critical | Dismissive | Integrative | most_frequent_discourse |
|---|---|---|---|---|---|
| Alabama | 2 | 0 | 0 | 0 | Biophysical |
| Arizona | 1 | 1 | 2 | 0 | Dismissive |
| California | 8 | 14 | 6 | 11 | Critical |
| Colorado | 7 | 4 | 3 | 1 | Biophysical |
| Florida | 5 | 3 | 15 | 0 | Dismissive |
| Georgia | 1 | 1 | 0 | 1 | Biophysical |
| Illinois | 6 | 2 | 5 | 1 | Biophysical |
| Iowa | 1 | 2 | 0 | 0 | Critical |
| Louisiana | 2 | 0 | 0 | 0 | Biophysical |
| Massachusetts | 13 | 2 | 3 | 1 | Biophysical |
| Michigan | 3 | 0 | 0 | 2 | Biophysical |
| New Jersey | 10 | 1 | 1 | 0 | Biophysical |
| New York | 12 | 8 | 2 | 10 | Biophysical |
| North Carolina | 1 | 0 | 2 | 0 | Dismissive |
| Ohio | 2 | 1 | 1 | 0 | Biophysical |
| Oregon | 10 | 5 | 0 | 1 | Biophysical |
| Texas | 3 | 5 | 14 | 2 | Dismissive |
| Utah | 4 | 0 | 1 | 0 | Biophysical |
| Virginia | 3 | 0 | 1 | 9 | Integrative |
| Washington | 7 | 3 | 1 | 2 | Biophysical |
| Washington, D.C. | 11 | 15 | 4 | 5 | Critical |
| Wisconsin | 3 | 1 | 3 | 4 | Integrative |
| Connecticut | 0 | 2 | 1 | 1 | Critical |
| Missouri | 0 | 3 | 5 | 0 | Dismissive |
| Montana | 0 | 1 | 0 | 0 | Critical |
| Nebraska | 0 | 1 | 0 | 0 | Critical |
| West Virginia | 0 | 2 | 1 | 1 | Critical |
| Arkansas | 0 | 0 | 1 | 0 | Dismissive |
| Delaware | 0 | 0 | 1 | 0 | Dismissive |
| Indiana | 0 | 0 | 1 | 0 | Dismissive |
| Kentucky | 0 | 0 | 1 | 0 | Dismissive |
| Maine | 0 | 0 | 3 | 0 | Dismissive |
| Maryland | 0 | 0 | 3 | 0 | Dismissive |
| Minnesota | 0 | 0 | 1 | 0 | Dismissive |
| Nevada | 0 | 0 | 3 | 1 | Dismissive |
| New Mexico | 0 | 0 | 1 | 0 | Dismissive |
| North Dakota | 0 | 0 | 1 | 0 | Dismissive |
| Pennsylvania | 0 | 0 | 1 | 0 | Dismissive |
| Wyoming | 0 | 0 | 1 | 0 | Dismissive |
| Alaska | 0 | 0 | 0 | 1 | Integrative |
| Oklahoma | 0 | 0 | 0 | 2 | Integrative |
| Tennessee | 0 | 0 | 0 | 1 | Integrative |
Finally, let’s visualize the most frequent discourse type per U.S. state.
library(ggplot2)
library(sf)
library(dplyr)
library(usmap)
# Load the U.S. map
us_states <- usmap::us_map(regions = "states")
# Convert the us_states to an sf object
us_states_sf <- st_as_sf(us_states, coords = c("x", "y"), crs = 4326, agr = "constant")
# Join the data
discourses_geo_summary_sf <- discourses_geo_summary %>%
left_join(us_states_sf, by = c("admin1_name" = "full"))
# Convert to an sf object, ensuring 'geom' is recognized as the geometry column
discourses_geo_summary_sf <- st_as_sf(discourses_geo_summary_sf, sf_column_name = "geom")
# Plot the map
ggplot(discourses_geo_summary_sf) +
geom_sf(aes(geometry = geom, fill = most_frequent_discourse), color = "black") +
scale_fill_manual(values = c(
"Biophysical" = "blue",
"Critical" = "red",
"Dismissive" = "green",
"Integrative" = "purple"
)) +
theme_minimal() +
labs(title = "Most Frequent Discourse Type per U.S. State")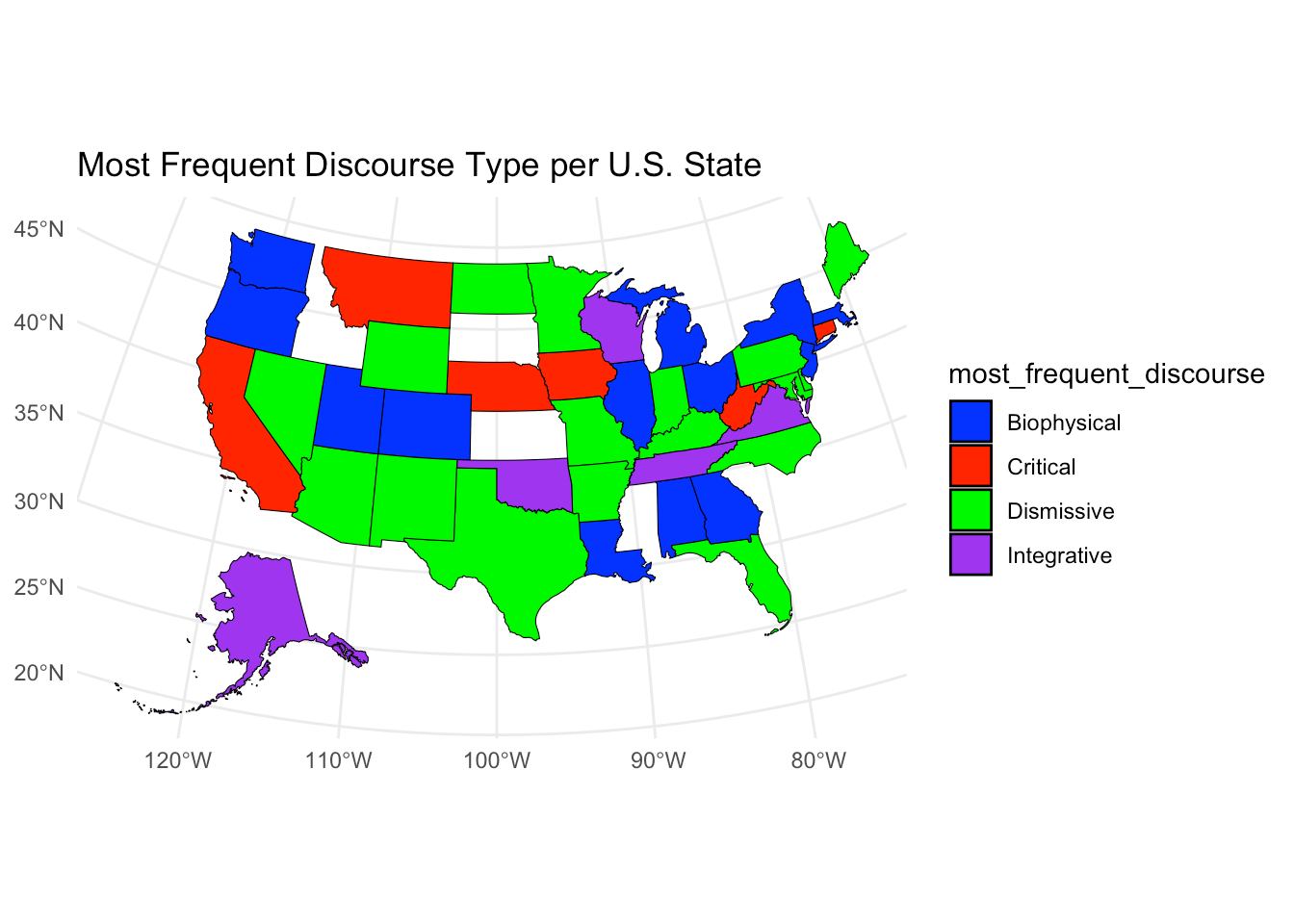
Next Steps
This prototype shows how we can leverage the data we collected to understand climate discourses by geography. But we’re not done yet.
In a next iteration, we will:
- Restart of data collection platform.
- Increase the number of social network platforms we collect data from.
- Increase the number of media sources that helps us capture climate conversations.
- Improve the AI agents to better classify the discourses.
- Develop a proper interactive data app to visualize the discourses and underlying narratives by geography. But also by time, to see how the discourses evolve.
For now though, I’m taking a few weeks off. So see you in September!