Thinking outside the MDS box

Considering different approaches to managing a data ecosystem
I still remember the excitement of discovering dbt and the Modern Data Stack ecosystem more than 5 years ago. Letting go of homegrown ETL systems built on Python scripts, SQL stored procedures and cron jobs. How liberating it was to adopt a suite of tools and principles that allowed us to confidently build robust data ecosystems for our users.
It could be argued that things have changed drastically since then, with the introduction of many new tools, new development patterns, new practices, etc. But I would probably not have been that surprised 5 years ago if I had had a glimpse into the present. The MDS is still alive and well!
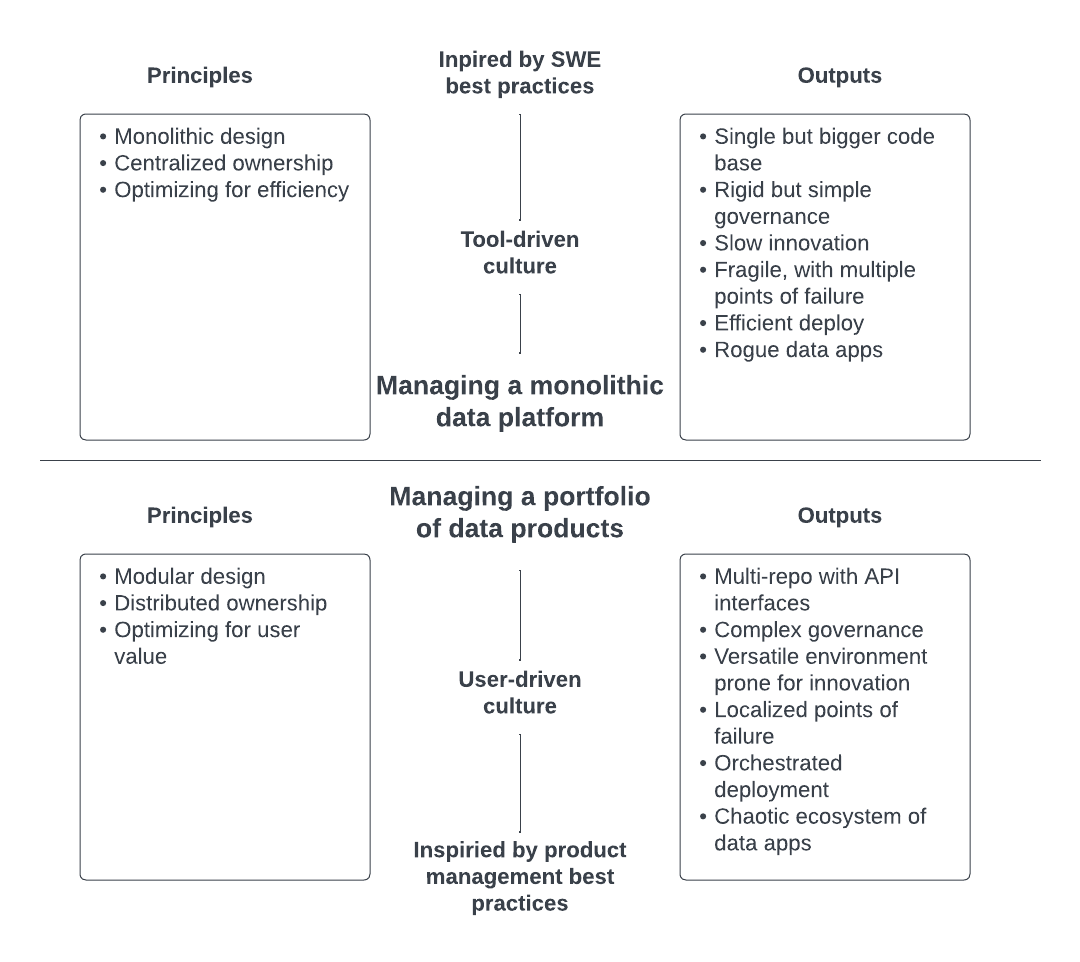
It’s reassuring how constant some of those underlying trends are. But just like software engineering keeps evolving, so should our data product-building practice. One major paradigm shift is how data teams can now manage a portfolio of data products instead of managing a monolithic data platform.
The idea of data product management is nothing new and has been well covered by Locally Optimistic in 2021. But what has changed since then is the introduction of the data mesh architecture, where you bundle data domains into distinct packages/products and use an orchestrator such as Dagster or dbt (Mesh) to stitch them back together.
This paradigm shift is not only architectural. It comes with different sets of principles, practices and outputs. Let’s dig into it.
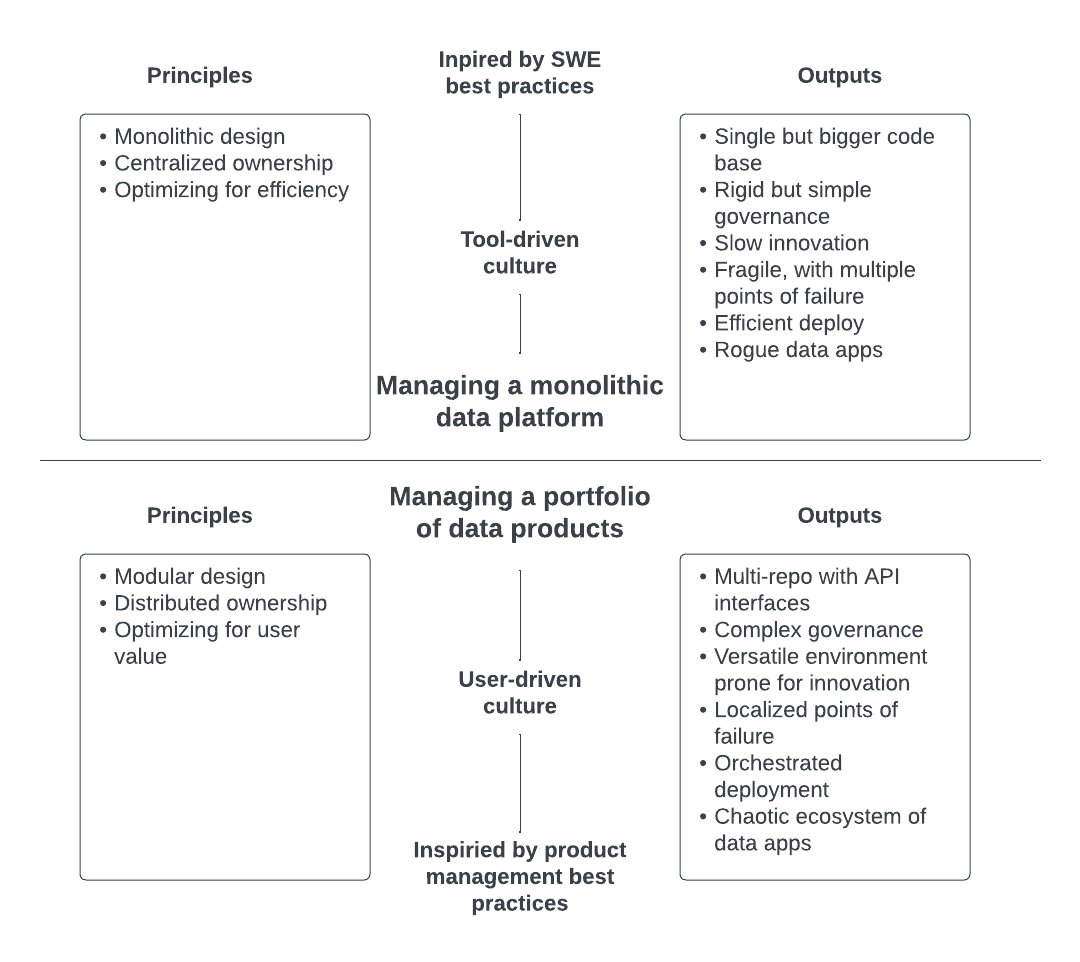
Let’s start by saying that both approaches have benefits and shortcomings and neither of them is suited for all data ecosystems. I’ve worked in very straightforward business analytics data stacks that were perfectly suited for a monolithic data ecosystem, whereas I’m also working with other ecosystems that are sprawling and require a paradigm shift.
There is a juncture point where you might need to consider your options. Consider this hypothetical data ecosystem…
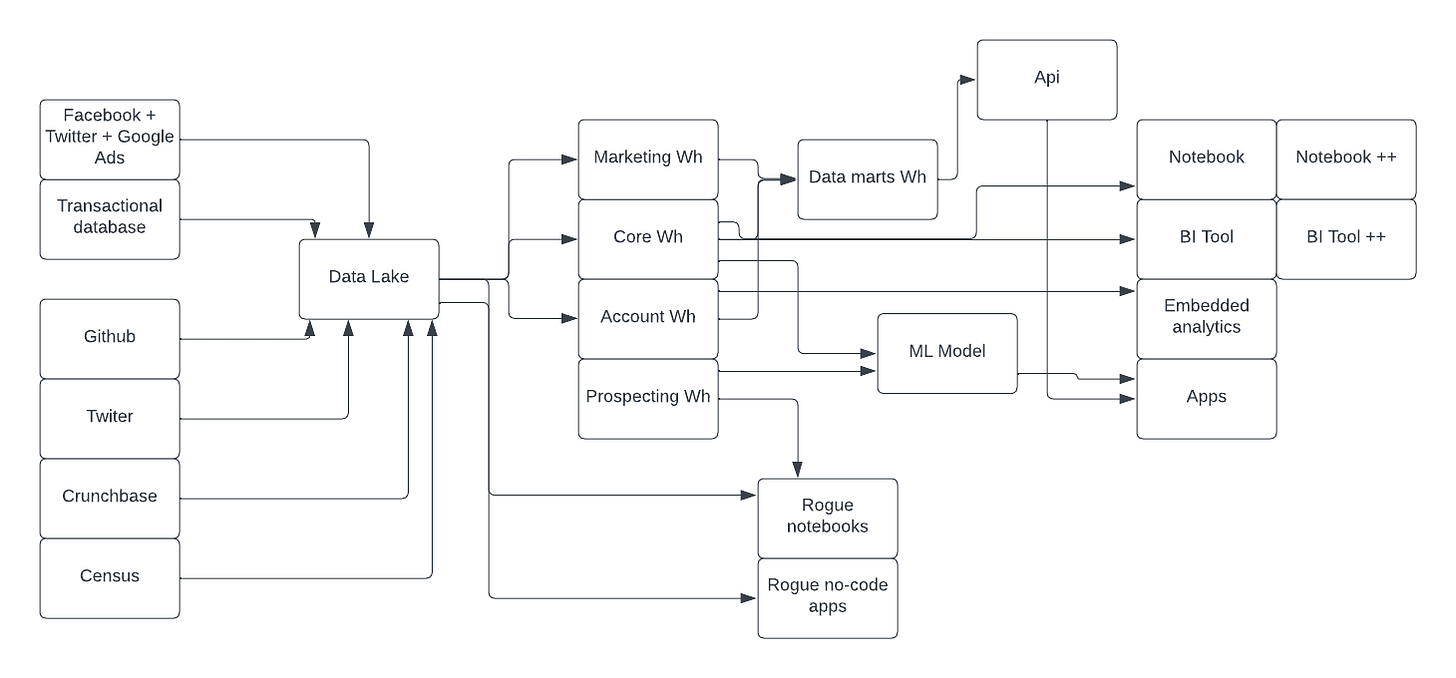
This ecosystem grew within a monolithic management paradigm and is probably on the verge of hitting a Cambrian explosion of data apps that will make it very difficult to maintain, let alone scale and innovate. Most end users are somewhat happy, even though failures are starting to creep in and make consistent results, let alone deployment of new features more difficult. Not only that, but we start seeing rogue data apps from users who cannot bear to have their data feature requests go through the proper planning and governance channels.
I would propose that it’s probably prudent for data teams to consider a shift in their management paradigm. Instead of managing a monolithic data platform, they are probably now in the business of managing a portfolio of data products.
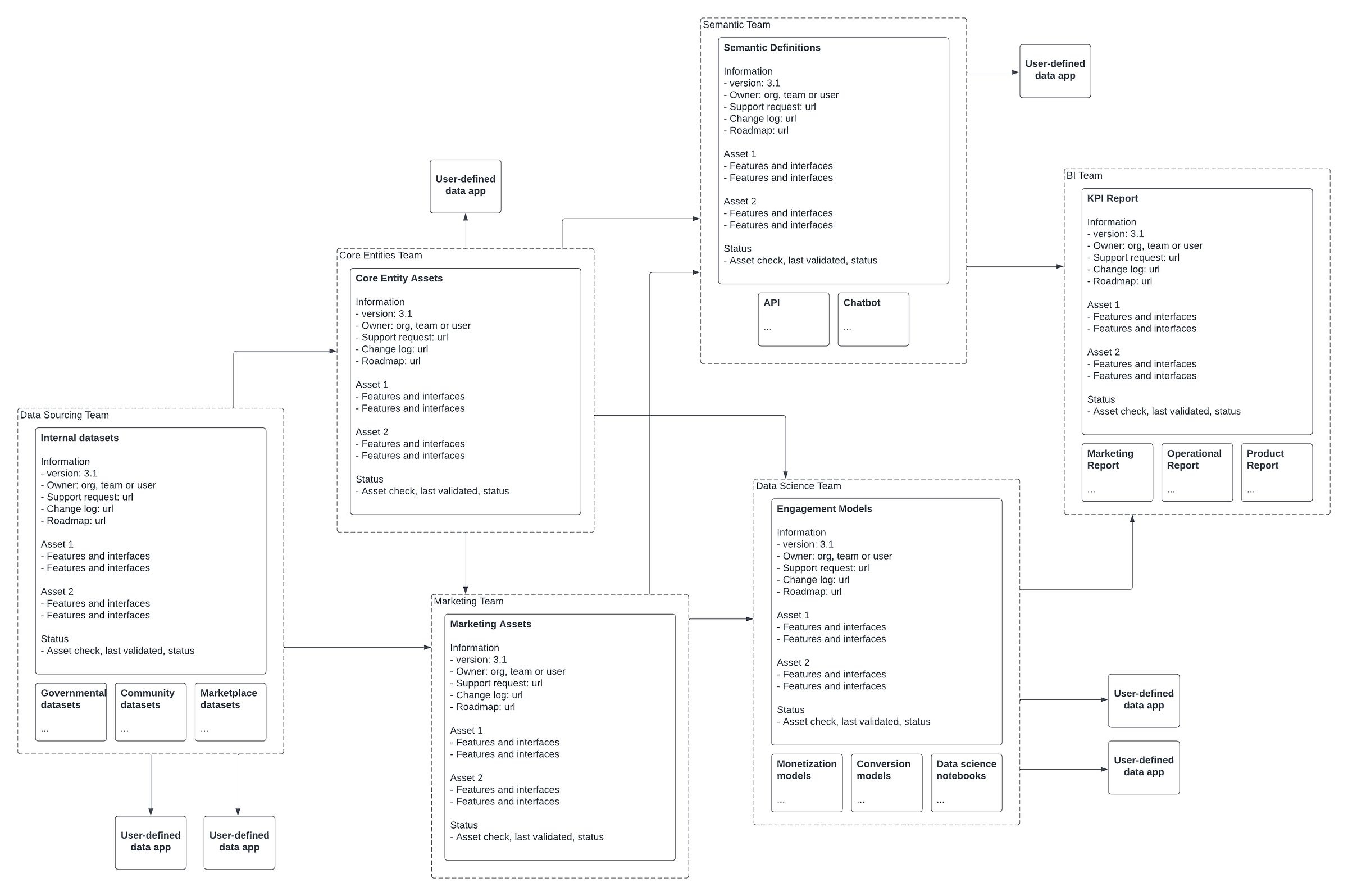
Whereas their previous paradigm focused on optimizing for efficiency, inspired by software engineering (SWE) best practices, this new paradigm is more user-centric, optimizing use value and borrowing from product management best practices. Teams are responsible for managing a suite of products that has external-facing data assets that can then be consumed by downstream data products or directly by user-defined data apps.
This leads to different management principles, which leads to different organizational structures, different roles and responsibilities. But also to different outputs. Again, it’s not about one architectural design being superior to the other, but the point is that you have different management paradigms at your disposal. One of them just might lead to outputs that are more in sync with your data ecosystem objectives.