Running a data mining operation using AI agents with Dagster and LangChain frameworks
Discover how we built a climate data platform using Dagster for orchestration, LangChain for AI agents, and OpenAI for data enrichment. The platform mines media articles and tracks social network conversations to analyze evolving climate narratives across time and geography.
 Olivier Dupuis
—
—
8 min read min read
Olivier Dupuis
—
—
8 min read min read
How we are building a data platform to capture online conversations about climate change.
The Climate Resilience Data Platform is designed to provide users with actionable insights into public perceptions of climate issues. The platform tracks and analyzes evolving climate narratives over time and across regions by mining data from various media sources and social networks.
An initial objective is to create an interactive map of climate discourses by region, similar to the static one we made in our prototype project.
In this post, we will go through how we built a data platform to mine climate-related articles and capture online conversations about those articles. We'll use Dagster, LangChain and OpenAI as the primary resources for this scraping and enrichment operation. Here's what we'll be going through:
📚 Table of Content
- Design
- Implementation
- Defining and orchestrating assets
- Setting up AI agents
- Enriching assets and tracing agent's performance
- Output
- Takeaways and Next Steps
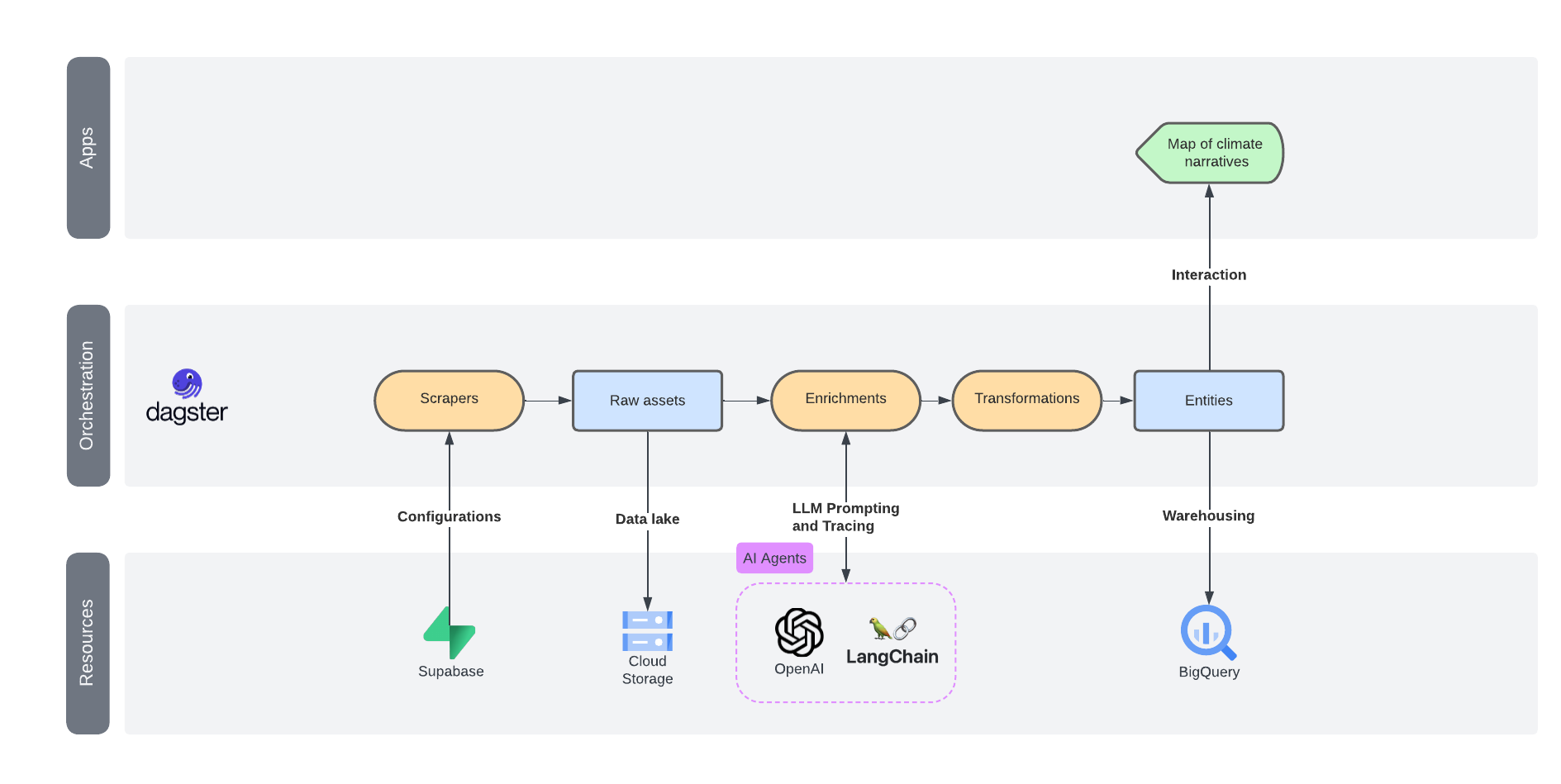
🏛️ Design
The platform is built on a layered, modular architecture emphasizing flexibility and scalability.
- Dagster is at the core, orchestrating workflows and ensuring data pipelines run smoothly.
- Supabase is used for configuration management
- OpenAI and LangChain are used to assemble and track AI agents which handle more complex data processing tasks.
One of the platform's key features is its ability to enrich data using AI agents in the transformation process. For example, we use agents to associate conversation posts with distinct climate discourse types. This allows for a more nuanced understanding of the public perception of climate issues and how those perceptions differ by geography and time.
What are AI agents? There are many definitions, but I rely on the one from Harrison Chase, co-founder and CEO at LangChain.
"An agent is a system that uses an LLM to decide the control flow of an application."
The definition is intentionally broad, referring to a quote from Andrew Ng:
"Rather than arguing over which work to include or exclude as being a true agent, we can acknowledge that there are different degrees to which systems can be agentic."
The point is that you might introduce an AI agent that incrementally becomes more autonomous. It doesn't become an agent when it reaches a central threshold but becomes more agentic with time.
Let's go deeper into the implementation of our scraping and enrichment operation.
🛠️ Implementation
What we will do
- We first want to define the data assets we produce throughout our platform.
- We will then set up AI agents that will contribute to the production of our assets.
- Finally, we will run our scraping and enrichment operation and trace our AI agents' performance.
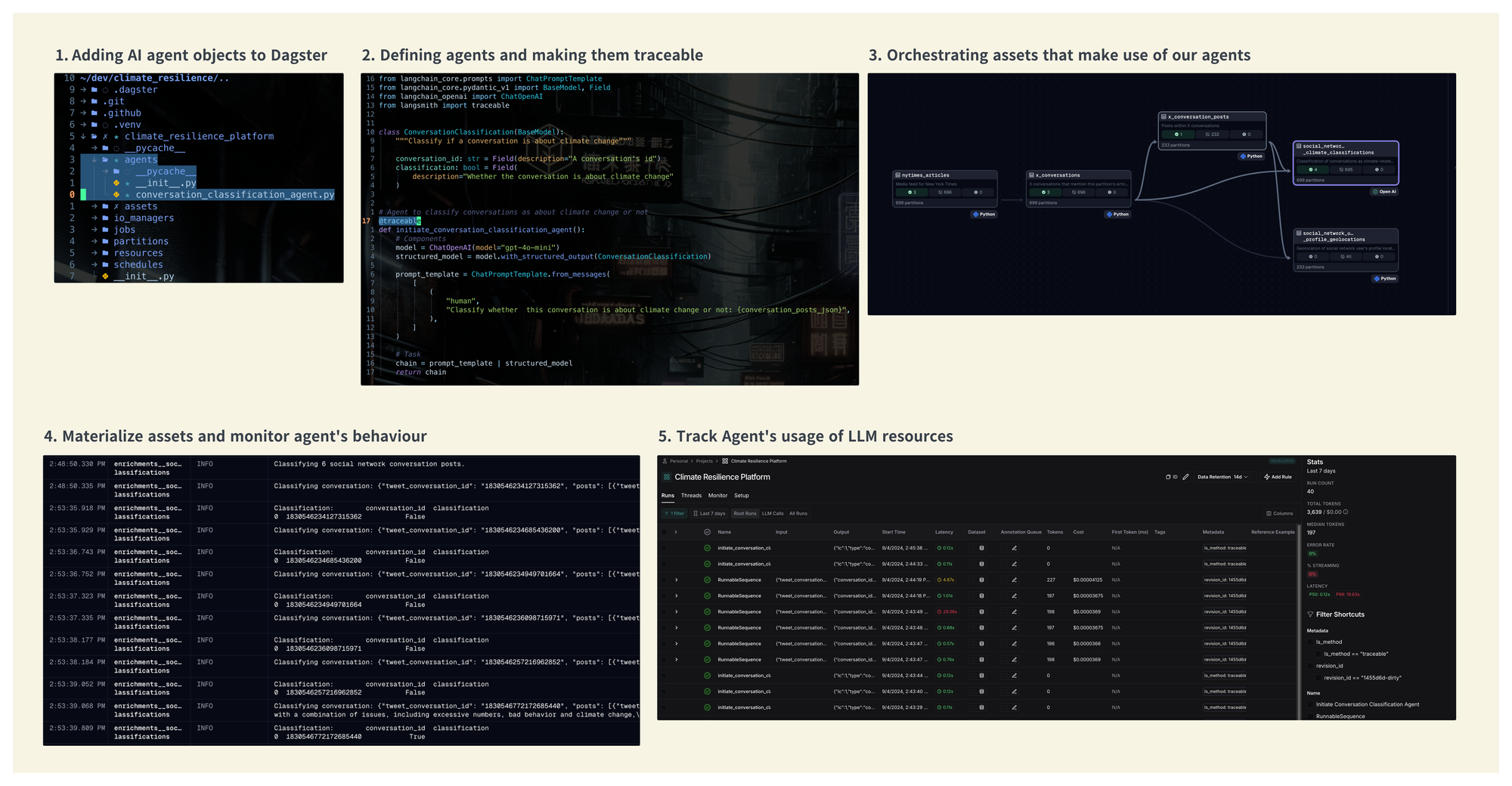
Defining and orchestrating assets
With Dagster, we can programmatically define what are the data assets that are produced by the platform. If you ask the AI chatbot from Dagster's documentation what assets are, it comes up with the following definition:
An asset in Dagster is an object in persistent storage that captures some understanding of the world. Examples of assets include:A database table or viewA file, such as one on your local machine or in blob storage like Amazon S3A machine learning model
Assets are the primary objects that data pipelines produce and manage. They represent the data that is stored and used across different applications.
A software-defined asset in Dagster is a declaration, in code, of an asset that should exist and a description of how to produce and update that asset. This approach enables a declarative method of data management, where the code is the source of truth for what data assets should exist and how they are computed.
An orchestrator such as Dagster holds the definition of those assets, leverages all resources required to produce and store their output, and builds relationships between assets. This is commonly known as the DAG (directed acyclic graph). Here's what our platform's DAG looks like.
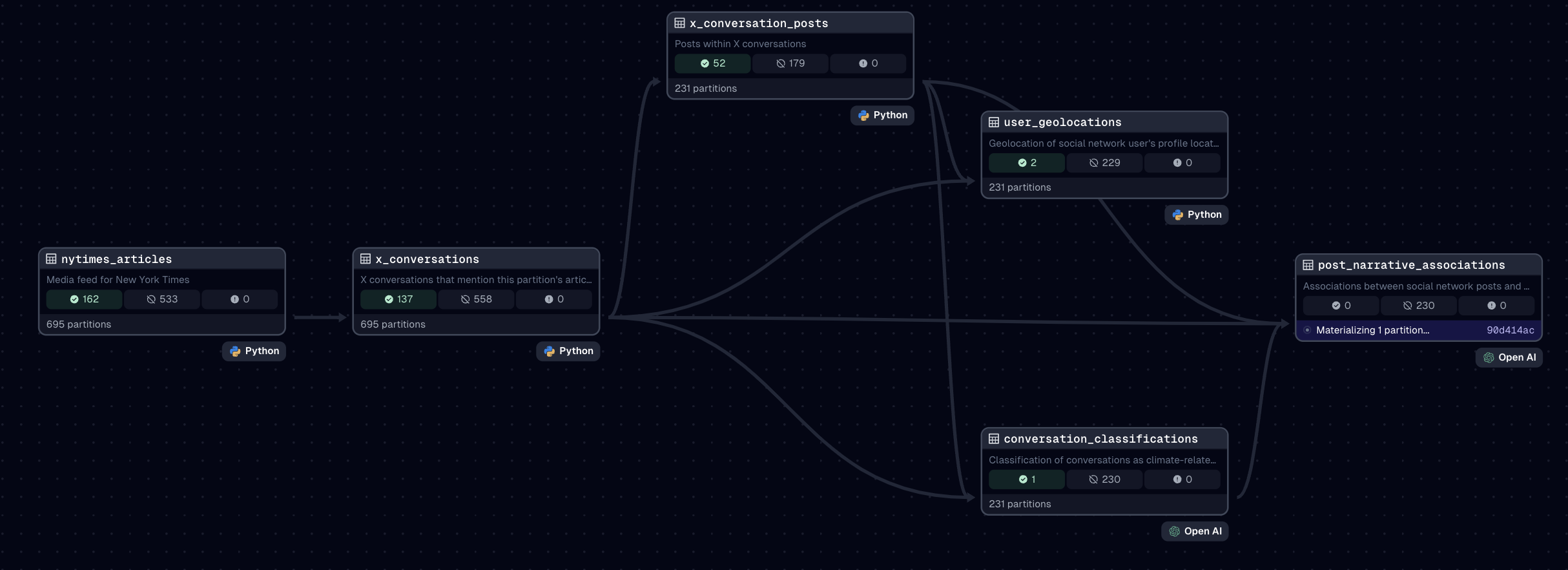
Just from this view, we can assess the status and performance of your data platform:
- What are the assets being produced by the platform?
- What are the relationships between assets?
- How many partitions (a slice of an asset) do they hold?
- How many of those partitions have successfully been produced?
- How many haven't?
- Which tool are we using to produce the asset?
The orchestrator holds information about what will be produced and has rich metadata about everything created (or failed to deliver).
Setting up AI agents
An orchestrator allows you to leverage any tool to produce your assets. In our case, we will be using AI agents assembled with the help of LangChain to perform transformations.
Specifically, we use an agent to classify conversations as whether they are discussing climate change. We also have an agent to associate each conversation's post with a narrative type.
In Dagster, we add those agents as another object type in our project's structure.
We use LangChain to define our agents, as it provides a framework for easily composing them, interacting with LLMs, injecting structure into prompts' outputs, and tracing the agent's performance.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langsmith import traceable
class ConversationClassification(BaseModel):
"""Classify if a conversation is about climate change"""
conversation_id: str = Field(description="A conversation's id")
classification: bool = Field(
description="Whether the conversation is about climate change"
)
# Agent to classify conversations as about climate change or not
@traceable
def initiate_conversation_classification_agent():
# Components
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(ConversationClassification)
prompt_template = ChatPromptTemplate.from_messages(
[
(
"human",
"Classify whether this conversation is about climate change or not: {conversation_posts_json}",
),
]
)
# Task
chain = prompt_template | structured_model
return chain
We can then use those agents within an asset definition to perform transformations. In the example below, we use our classification agent downstream of our scraping operation to classify conversations as to whether they relate to climate change.
from ..agents import conversation_classification_agent, post_association_agent
@asset(
name="conversation_classifications",
key_prefix=["enrichments"],
description="Classification of conversations as climate-related or not",
io_manager_key="bigquery_io_manager",
ins={
"x_conversations": AssetIn(
key=["social_networks", "x_conversations"],
partition_mapping=TimeWindowPartitionMapping(
start_offset=-4, end_offset=-4
),
),
"x_conversation_posts": AssetIn(
key=["social_networks", "x_conversation_posts"],
partition_mapping=TimeWindowPartitionMapping(start_offset=-4, end_offset=0),
),
},
partitions_def=three_hour_partition_def,
metadata={"partition_expr": "partition_time"},
compute_kind="openai",
)
def conversation_classifications(
context,
x_conversations,
x_conversation_posts,
):
if not x_conversations.empty:
# Assemble full conversations
conversations_df = assemble_conversations(x_conversations, x_conversation_posts)
# Group by tweet_conversation_id and aggregate tweet_texts into a list ordered by tweet_created_at
conversations_df = (
conversations_df.groupby("tweet_conversation_id")
.apply(
lambda x: x.sort_values("tweet_created_at")[
["tweet_id", "tweet_created_at", "tweet_text"]
].to_dict(orient="records")
)
.reset_index(name="posts")
)
# Iterate over all conversations and classify them
for _, conversation_df in conversations_df.iterrows():
conversation_dict = conversation_df.to_dict()
conversation_json = json.dumps(conversation_dict)
conversation_classifications_output = (
conversation_classification_agent.invoke(
{"conversation_posts_json": conversation_json}
)
)
new_classification = pd.DataFrame(
[conversation_classifications_output.dict()]
)
conversation_classifications_df = pd.concat(
[conversation_classifications_df, new_classification], ignore_index=True
)
# Append partition time to DataFrame
conversation_classifications_df["partition_time"] = partition_time
# Return asset
yield Output(
value=conversation_classifications_df,
metadata={
"num_rows": conversation_classifications_df.shape[0],
},
)
Enriching assets and tracing agent's performance
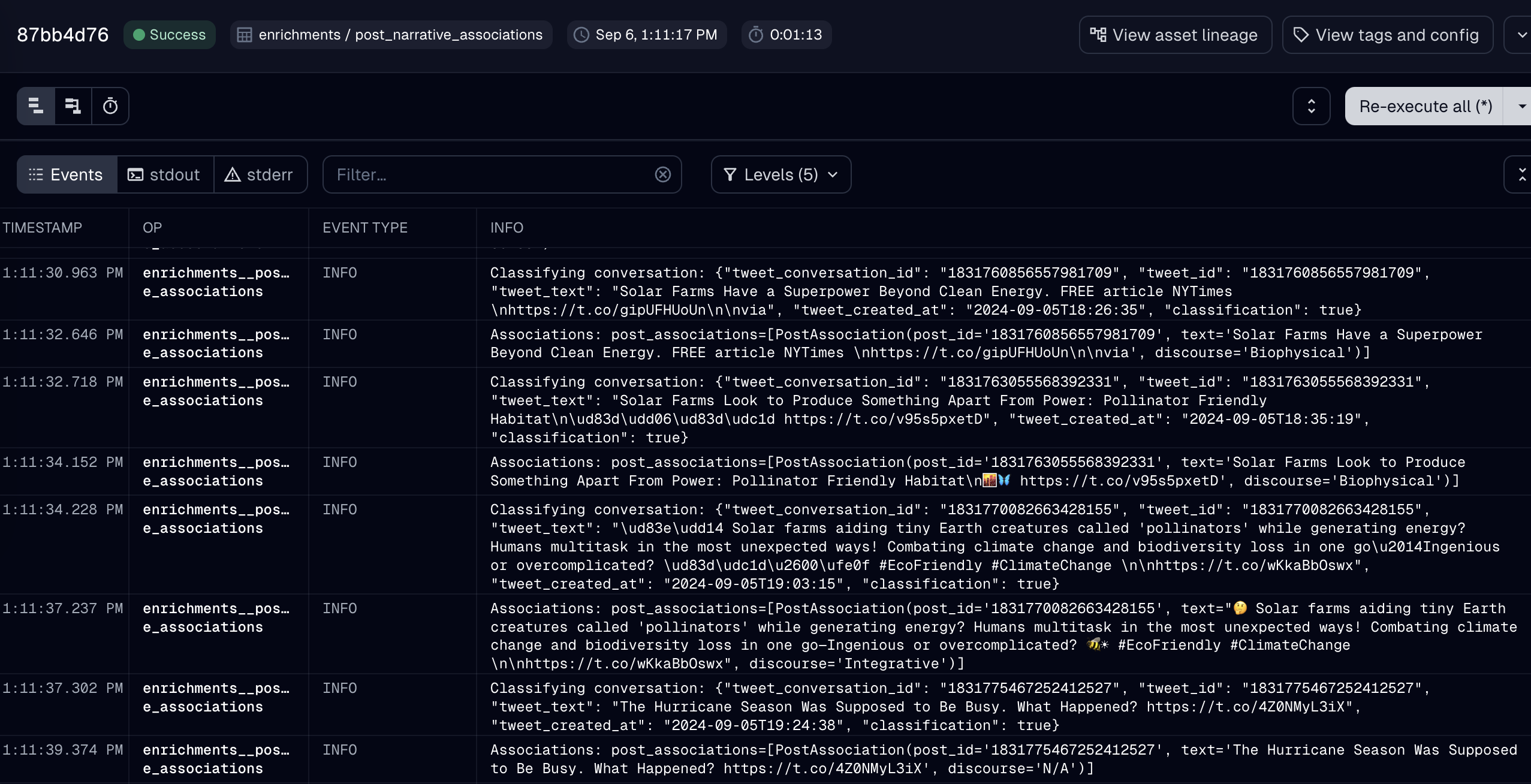
We can log the agent's actions when we run an asset that uses an AI agent. Here, we see the structured output of the narrative association performed for each post.
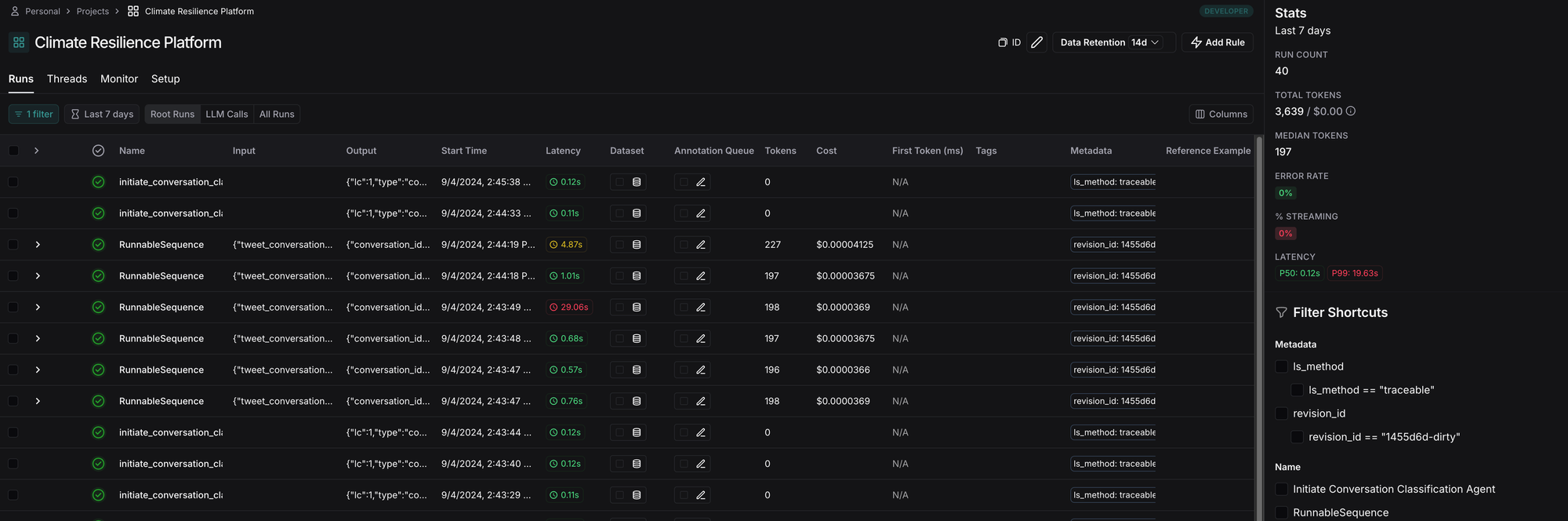
With the LangChain framework, you can trace your agents' performance through their LangSmith product. It's like an extension of your orchestration's monitoring. It provides essential information such as latency, tokens generated, costs, prompts produced, outputs received, etc.
📦 Output
As we saw with our DAG, the platform is producing six assets:
- New York Times articles that are covering climate events.
- X (Twitter) conversations about those articles.
- X posts from those articles.
- User geolocations based on their profile descriptions.
- Classification of conversations to ensure they are on-topic.
- Association of narrative types to individual posts.
Let's perform a query of those raw tables.
with s_conversation_classifications as (
select conversation_id
from climate_resilience.conversation_classifications
where classification is true
),
s_conversations as (
select * from climate_resilience.x_conversations
),
s_conversation_posts as (
select * from climate_resilience.x_conversation_posts
),
s_user_geolocations as (
select distinct
social_network_profile_id,
first_value(location) over (partition by social_network_profile_id order by geolocation_ts, location_order) as location,
first_value(COUNTRYNAME) over (partition by social_network_profile_id order by geolocation_ts, location_order) as country_name,
first_value(COUNTRYCODE) over (partition by social_network_profile_id order by geolocation_ts, location_order) as country_code,
first_value(ADMINNAME1) over (partition by social_network_profile_id order by geolocation_ts, location_order) as admin_name,
first_value(ADMINCODE1) over (partition by social_network_profile_id order by geolocation_ts, location_order) as admin_code,
first_value(latitude) over (partition by social_network_profile_id order by geolocation_ts, location_order) as latitude,
first_value(longitude) over (partition by social_network_profile_id order by geolocation_ts, location_order) as longitude
from climate_resilience.user_geolocations
),
s_post_narrative_associations as (
select * from climate_resilience.post_narrative_associations
),
merge_posts as (
select
s_conversations.tweet_id as post_id,
s_conversations.tweet_conversation_id as conversation_id,
s_conversations.tweet_text as post_text,
s_conversations.author_id,
s_conversations.author_username,
s_conversations.tweet_created_at as post_publication_ts
from s_conversations
union all
select
s_conversation_posts.tweet_id as post_id,
s_conversation_posts.tweet_conversation_id as conversation_id,
s_conversation_posts.tweet_text as post_text,
s_conversation_posts.author_id,
s_conversation_posts.author_username,
s_conversation_posts.tweet_created_at as post_publication_ts
from s_conversation_posts
),
filter_climate_conversations as (
select merge_posts.* from merge_posts
inner join s_conversation_classifications on merge_posts.conversation_id = s_conversation_classifications.conversation_id
),
final as (
select distinct
filter_climate_conversations.conversation_id,
filter_climate_conversations.post_id,
filter_climate_conversations.post_text,
filter_climate_conversations.post_publication_ts,
filter_climate_conversations.author_username,
s_user_geolocations.location,
s_user_geolocations.country_name,
s_user_geolocations.country_code,
s_user_geolocations.admin_name,
s_user_geolocations.admin_code,
s_user_geolocations.latitude,
s_user_geolocations.longitude,
s_post_narrative_associations.discourse_type
from filter_climate_conversations
left join s_user_geolocations on filter_climate_conversations.author_id = s_user_geolocations.social_network_profile_id
left join s_post_narrative_associations on filter_climate_conversations.post_id = s_post_narrative_associations.post_id
)
select * from final
order by post_publication_ts
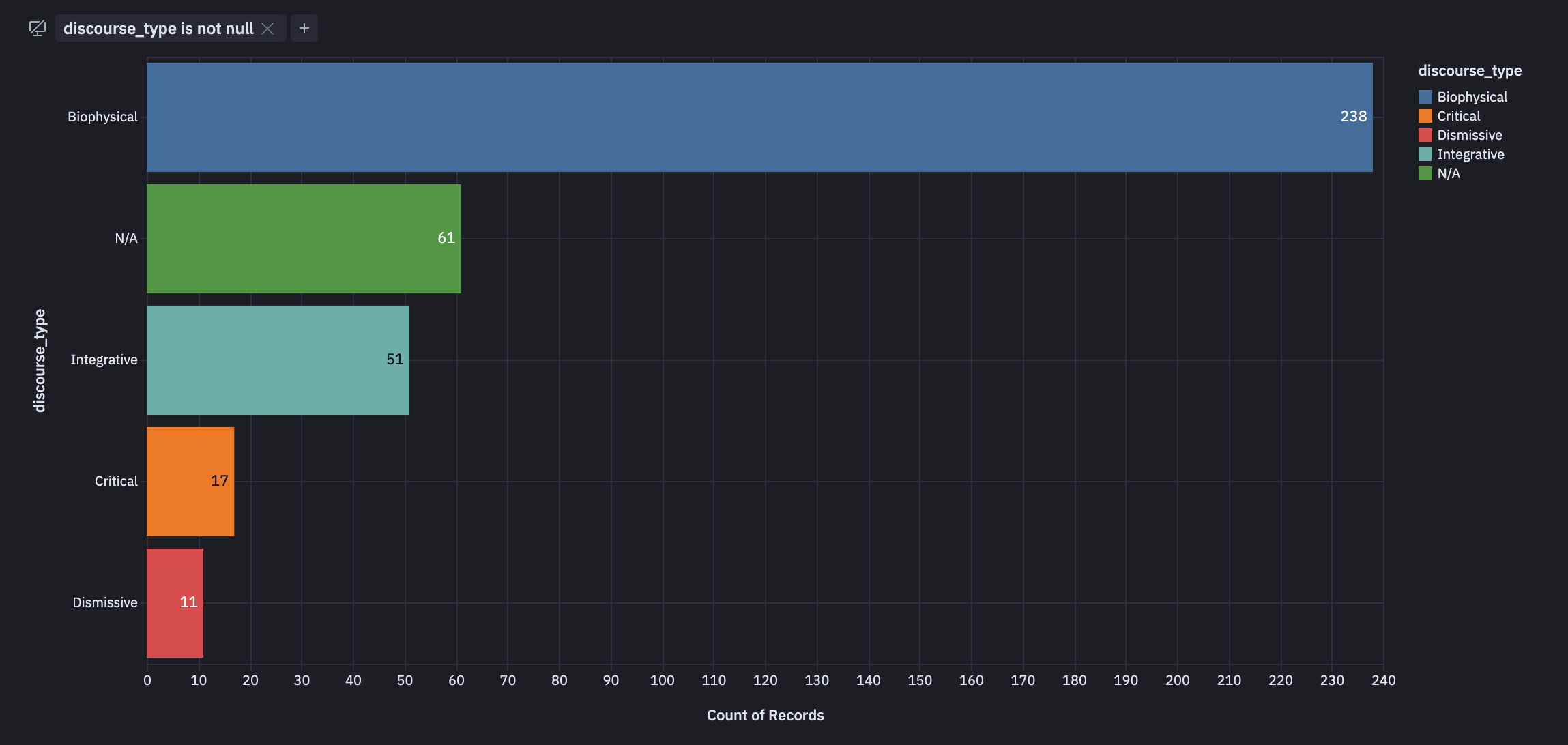
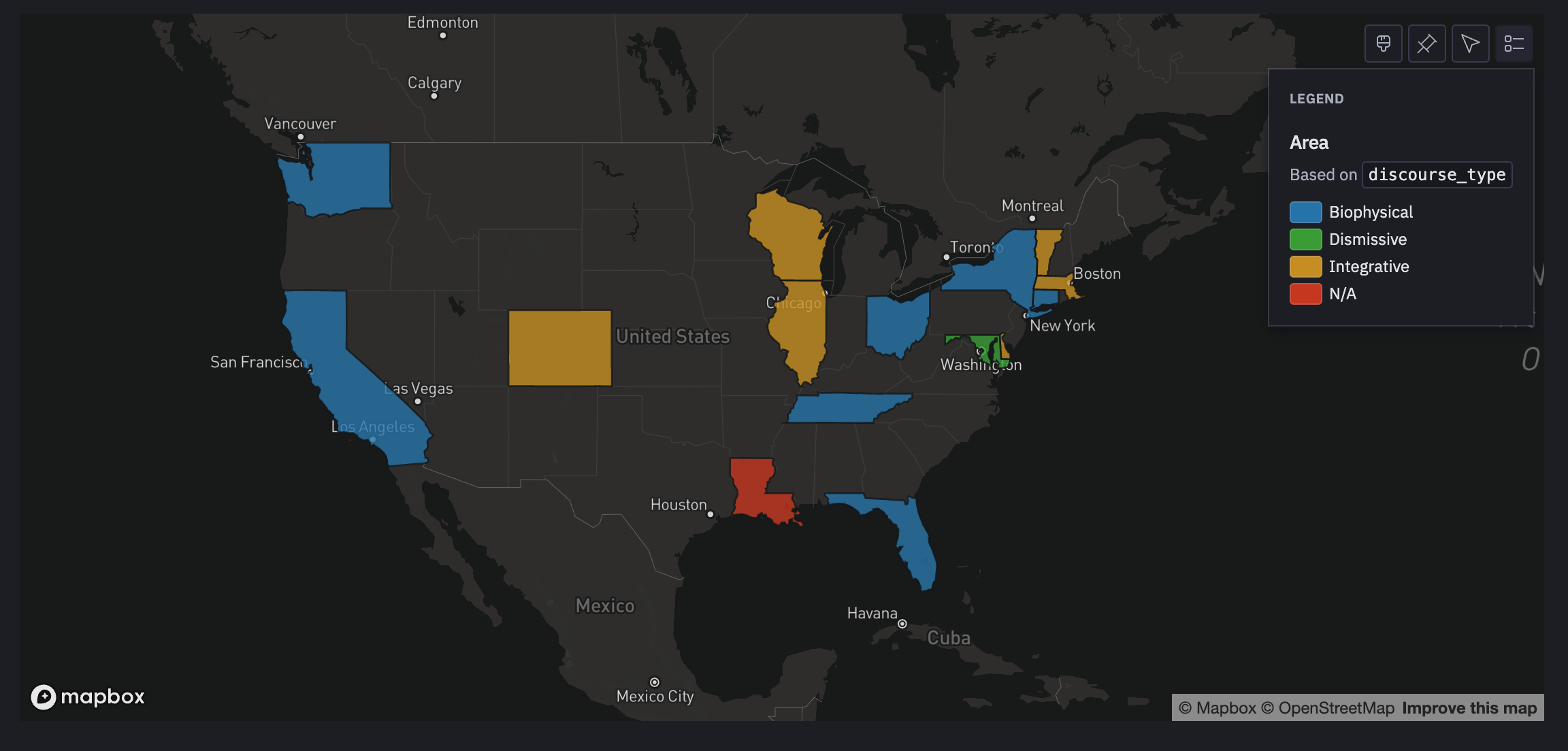
We only have a few days' worth of data, but let's see if we can start visualizing discourse types by geography. Let's start by looking at the distribution of discourse types.
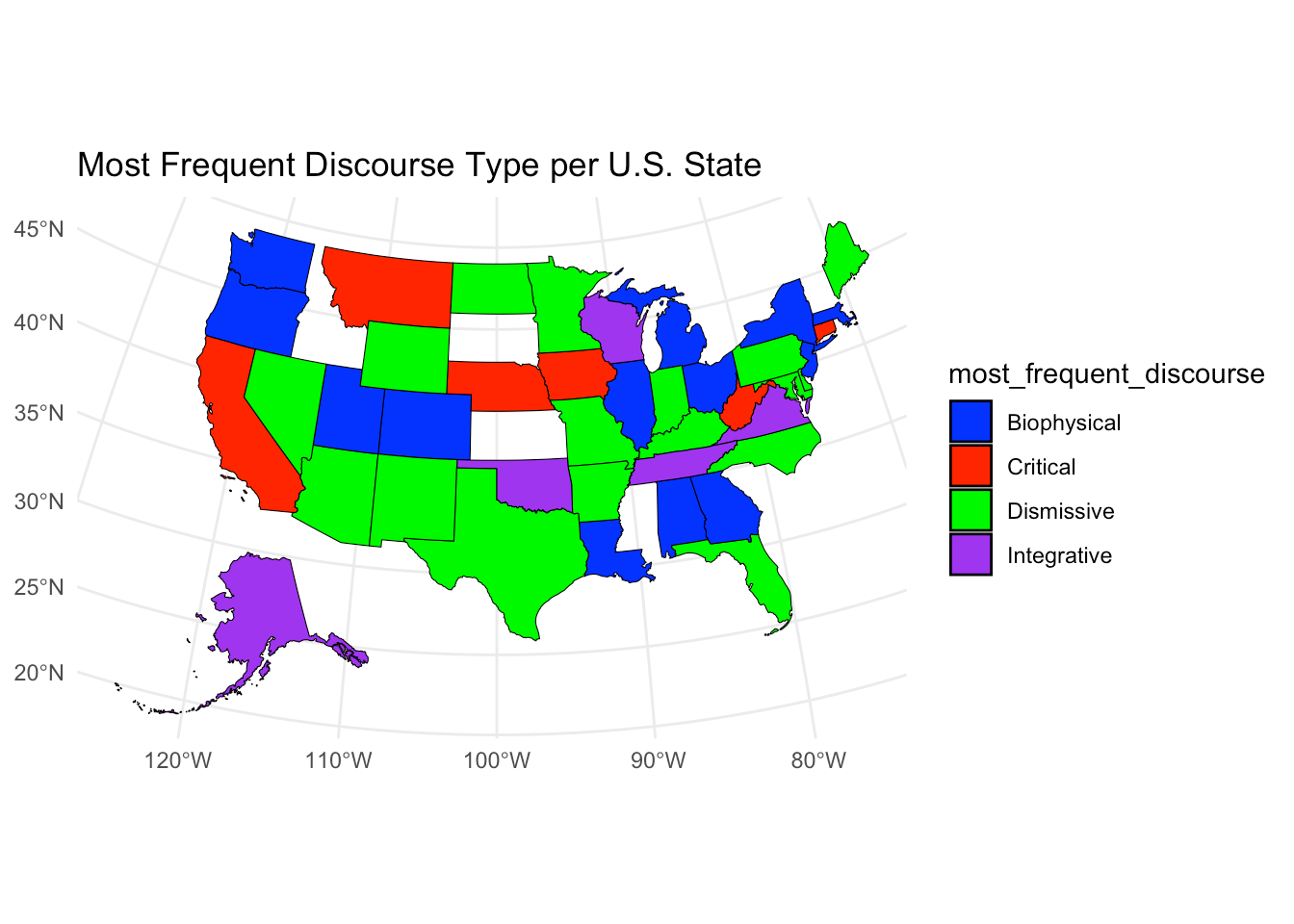
And now let's see a very preliminary map of the dominant narratives by U.S. state.
📝 Takeaways and Next Steps
So, what are the key takeaways from this?
- LLMs are not just for end users to interact with your data; they can be used deep within your ETL process.
- Using the right frameworks (in our case, Dagster and LangChain), it's easy to set up AI agents and have them take an active role in your transformation assets.
- With rich and robust metadata collection from both our frameworks, we can closely monitor the performance of our agents and the amount we spend on LLM calls. That opens up many opportunities to test out different models and optimize your prompts.
We are only starting with this platform, and it's already producing some exciting data. There are many opportunities to build data products that will consume this data. But the next step will be to improve the geolocation enrichment process, warehouse entities, and create an interactive app to explore how climate narratives change through geography and time.